

ادوارد تلر ، فیزیک دان معروف ، توصیف زیر را درباره حقیقت و فرضیه ، بیان کرده است:
یک حقیقت، یک عبارت ساده است که همه آنرا قبول دارند. این حقیقت، بی گناه و مصون از خطاست تا زمانی که نقص یا ایرادی در آن پدید آید. یک فرضیه ، یک پیشنهاد جدید و بدیع است که کسی نمی خواهد آنرا قبول کند. فرضیه، موجودی گناهکار است مگر اینکه ثابت شود، موثر و مفید است <و می توان با آن بعضی پدیده ها را توضیح داد> آزمایش فرضیه پژوهش
آزمایش فرضیه، یک پدیده غالب و کاربردی در علم داده است. مانند یک داستان جنایی، که با دنبال کردن یک فرضیه، به صحت و سقم آن، به تدریج پی می بریم، در آزمایش فرضیه هم از یک فرضیه ابتدایی و خام ، به یک گزاره و قضیه موثر می رسیم.
در بسیاری از موارد، بر اساس داده های به دست آمده، می خواهیم مطلبی را ثابت کنیم یا به نتیجه ای برسیم. بر اساس این داده ها فرضیه ای بنا می کنیم و نتیجه ای میگیریم که این نتیجه ممکن است درست باشد حال باید بتوانیم فرضیه خودمان را با بررسی های بیشتر و نیز با استفاده از علم آمار و بررسی عدم شانسی بودن داده های به دست آمده، ثابت کرده و یا آنرا رد کنیم. در این مواقع، به سراغ مفهوم مهم آزمایش فرضیه که ریشه در علم آمار دارد، می رویم . در این مقاله با بررسی یک مثال ساده، روال معمول و مفاهیم اصلی این بخش از علم داده را با هم مرور می کنیم.
آزمون فرضیه تحقیق یک فرآیند اساسی در تحقیقات علمی است که شامل استنباط های آماری در مورد یک جامعه بر اساس نمونه ای از داده ها است. آزمون فرضیه به محققان اجازه می دهد تا تعیین کنند که آیا فرضیه ها یا ادعاهای آنها در مورد یک جمعیت توسط شواهد ارائه شده توسط نمونه پشتیبانی می شود یا خیر.
در اینجا مراحل کلی درگیر در آزمون فرضیه تحقیق آمده است:
فرمول بندی فرضیه ها:
با بیان یک فرضیه صفر (H0) و یک فرضیه جایگزین (Ha یا H1) شروع کنید. فرضیه صفر معمولاً وضعیت موجود یا عدم تأثیر را نشان می دهد، در حالی که فرضیه جایگزین بیان می کند که محقق سعی دارد نشان دهد.
یک سطح اهمیت (آلفا) را انتخاب کنید:
سطح معناداری (آلفا) را انتخاب کنید که آستانه تعیین معنیداری آماری را مشخص میکند. مقادیر رایج مورد استفاده 0.05 (5%) یا 0.01 (1%) هستند.
جمع آوری داده ها:
دادهها را از نمونهای جمعآوری کنید که نماینده جمعیتی است که شما علاقهمند به مطالعه آن هستید.
یک آزمون آماری را انتخاب کنید:
یک آزمون آماری مناسب بر اساس ماهیت داده ها و سوال تحقیق خود انتخاب کنید. انتخاب آزمون به عواملی مانند نوع داده ها (به عنوان مثال طبقه بندی، پیوسته) و تعداد گروه های مورد مقایسه بستگی دارد.
محاسبه آمار آزمون:
با استفاده از داده های جمع آوری شده، آمار آزمون مناسب را محاسبه کنید. این آمار تفاوت یا رابطه مشاهده شده بین گروه ها یا متغیرها را کمی می کند.
P-Value را تعیین کنید:
p-value معیاری برای شواهد در برابر فرضیه صفر است. در صورت صحت فرضیه صفر، احتمال مشاهده نتایج به دست آمده (یا نتایج شدیدتر) را نشان می دهد. مقدار p کوچکتر شواهد قوی تری را در برابر فرضیه صفر نشان می دهد.
مقایسه P-Value با سطح اهمیت:
اگر مقدار p کمتر یا مساوی سطح اهمیت انتخابی (آلفا) باشد، شما فرضیه صفر را به نفع فرضیه جایگزین رد می کنید. این نشان می دهد که نتایج مشاهده شده بعید است که به صورت تصادفی به تنهایی رخ دهند.
نتیجه گیری کن:
بر اساس نتایج آزمون فرضیه، در مورد اینکه آیا یافته های شما از فرضیه تحقیق حمایت می کند یا خیر، نتیجه گیری کنید. اگر فرضیه صفر رد شود، ممکن است به این نتیجه برسید که شواهدی دال بر اثر، رابطه یا تفاوت وجود دارد.
اهمیت عملی را در نظر بگیرید:
حتی اگر یک نتیجه از نظر آماری معنی دار باشد، مهم است که در نظر بگیرید که آیا اندازه اثر مشاهده شده در زمینه تحقیق شما معنی دار است یا خیر.
گزارش نتایج:
نتایج آزمون فرضیه خود را به وضوح گزارش کنید، از جمله p-value، تصمیم در مورد فرضیه صفر، و هر اندازه اثر مرتبط یا فواصل اطمینان.
توجه به این نکته ضروری است که آزمون فرضیه شواهدی را علیه فرضیه صفر ارائه می دهد، اما صحت فرضیه جایگزین را ثابت نمی کند. این ابزاری برای تصمیم گیری آگاهانه بر اساس شواهد موجود است. علاوه بر این، بررسی دقیق طرح آزمایشی، حجم نمونه و سایر عوامل برای اطمینان از نتایج معتبر و قابل اعتماد از آزمون فرضیه ضروری است.
Hypothesis از کلمه یونانی hupo به معنای «زیر» و thesis به معنای جایگذاری یا نشات گرفته است و به معنی ایده ایست که در حال حاضر دست کم گرفته شده است و با مدارک و مشاهدات محدود، به دست آمده است و پایه ای برای تحقیقات بعدی است.
آزمایش فرضیه و راستی آزمایی آن، از مراحل زیر تشکیل شده است:
پیش فرض های مورد نیاز را تعیین کنید.
فرضیه اصلی را مشخص کنید.
فرضیه جایگزین را تعیین کنید.
شرایط قبول و پذیرش فرضیه را تعیین کنید.
آزمایش های لازم را برای سنجش فرضیه ها انجام دهید.
نتایج را ارزیابی کنید. آیا نتایج، فرضیه اصلی را تایید می کنند؟ آیا مطمئن هستیم که نتایج شانسی نیستند و می توان به آنها اعتماد کرد ؟
تصمیم نهایی را بگیرید : فرضیه اول را با پذیرش فرضیه جایگزین رد کنید و یا اعلام کنید که فرضیه اصلی با مدارک موجود، قابل رد شدن نیست.
برای شرح فرآیند آزمون فرضیه، یک مثال عملی می زنیم. هلماویک (Holmavik)، شهری کوچک در بخش غربی ایسلند است. این شهر یک موزه منحصربفرد جادوگری دارد و جالب اینجاست که هنوز هم افرادی در این شهر هستند که ادعای جادوگر بودن می کنند. جان و ایزاک دو نفر از این جور افراد هستند که ادعا می کنند جادوگرند البته ادعای بزرگی هم ندارند و فقط میگویند که می توانند نهان بینی کنند یعنی در بازی چهاربرگ(پاسور)، اگر برگی را از پشت به آنها نشان بدهیم، می توانند گروه چهارگانه آنرا به درستی حدس بزنند (نوع برگ). می خواهیم این موضوع را از لحاظ آماری بررسی کنیم .
قوانین بازی نهان بینی کارتهای بازی چهاربرگ از قرار زیر است :
به جان و ایزاک ده کارت که به صورت تصادفی انتخاب شده اند، از پشت نمایش داده می شود و از آنها خواسته میشود که تعیین کنند نوع برگ هر کدام از کارت چیست.
پاسخ های ده گانه هر بازیکن ثبت شده و با مقدار صحیح کارت ها مقایسه می شود. نتایج یادداشت خواهد شد آزمایش فرضیه پژوهش
این کار ، ده بار تکرار میشود.
به طور طبیعی علم آمار نشان داده است که به صورت میانگین، ۶ حدس از ده حدس می تواند صحیح باشد. بنابراین پایه استنتاج را بر این عدد بنا می کنیم و از لحاظ آماری تعیین می کنیم که جان و ایزاک می توانند جادوگر باشند یا نه .
گام یک : تعیین فرضیات
تعیین فرضیات اصلی مساله، کاملاً به ماهیت آن بستگی دارد و نمی توان فرمولی کلی برای آن ارائه کرد. هر چند مسائلی مانند توزیع آماری داده ها و نحوه انتخاب داده های نمونه برای بررسی فرضیه، جزء حداقل هایی است که باید تعیین شود.
توزیع آماری داده ها : داده ها معمولاً الگوی مشخصی دارند که توزیع های آماری هم برای فهم و بیان آنها به وجود آمده اند. بسیاری از داده های دنیای واقعی مانند قیمت های سهام، وزن و قد افراد شرکت کننده در یک جشن، مصرف سوخت متوسط ماشین های یک پارکینگ و مانند آن، توزیع نرمال و یکنواختی دارند. توزیع نرمال به صورت ساده یعنی اینکه اغلب داده ها، حول و حوش یک مقدار میانه قرار دارند. منظور از میانه هم عددی است که دقیقاً در وسط قرار میگیرد و ممکن است با میانگین داده ها کمی متفاوت باشد.
نمونه گیری : فرض بر این است که داده های جمع آوری شده برای آزمایش فرضیه، کاملاً تصادفی انتخاب شده و سوگیری خاصی ندارند.
برای بازی نهان بینی این فرضیات به صورت زیر در خواهند آمد:
توزیع آماری کارت های انتخاب شده، توزیع نرمال خواهد بود که اگر کارت ها به صورت کاملا تصادفی انتخاب شوند، فرضی درست خواهد بود.
کارت ها در این بازی کاملاً یکنواخت و مشابه بوده و سوگیری خاصی ندارند.
گام دو : فرضیه صفر (NULL Hypothesis) – H0
همانطور که اشاره شد، فرضیه صفر، حدس اولیه و اصلی ماست و فرض بر این است که در حال حاضر این فرضیه، معتبر است. قرار است دلایلی برای رد آن بیابیم و یا اعلام کنیم دلایلی برای رد آن، پیدا نشده است.
برای بازی نهان بینی فرضیه صفر ما از قرار زیر است: آزمایش فرضیه پژوهش
جان و ایزاک، نهان بین نیستند (H0)
یعنی فرض ما بر این است که این دو نفر فقط خوش شانس هستند و حدسیات آنها ، بر مبنای تصادف است نکته : به طور معمول، فرضیه صفر حالتی در نظر گرفته می شود که نمونه های به دست آمده، تفاوت معناداری با جامعه اصلی ندارند.
گام سوم : فرضیه جایگزین (Alternate Hypothesis) – Ha
فرضیه جایگزین، فرضیه مخالف با فرضیه صفر است. اگر این فرضیه از لحاظ آماری تایید شود، به معنای رد شدن فرضیه صفر خواهد بود. فرضیه جایگزین ما برای بازی فوق از قرار زیر است:
جان و ایزاک ، نهان بین هستند (Ha)
گام چهارم : شرط پذیرش
فرضیه اصلی ما فرضیه صفر است که باید برای تایید آن، از دانش حوزه کار و آماری که داریم، کمک بگیریم و یک عدد یا آستانه پذیرش برای قبول کردن یا عدم قبول فرضیه خود، تعیین نماییم. از لحاظ آماری، مشخص شده است که یک شخص معمولی تا ۶ بار از ۱۰ بازی را می تواند، خال یا برگ یک کارت را درست حدس بزند. این عدد را معیار پذیرش فرضیه صفر در نظر میگیریم یعنی اگر جان و ایزاک تا این عدد را حدس زدند، فرضیه صفر ما درست بوده و این دو نفر، فقط خوش شانس هستند.
اگر جان و ایزاک، بیشتر از این مقدار را درست حدس بزنند، مدرک بیشتری برای جادوگر بودن آنها، به دست آمده است. زمانی که تعداد آزمایش ها را برای جان و ایزاک تکرار کنیم و میانگین حدس های درست آنها را به دست آوریم، مبنایی برای مقایسه حاصل شده است. قبل از اینکه بر مبنای این عدد به دست آمده، تصمیم نهایی را بگیریم، با توجه به اینکه ممکن است نتایج شانسی بوده و یا سوگیری خاصی داشته باشد، باید از علم آمار برای تحلیل درست نتابج کمک بگیریم.یعنی باید بررسی کنیم که این مقدار تا چه حد از میانگین طبیعی جامعه یا همان عدد ۶ فاصله دارد و این اختلاف، از چه حدی اگر بیشتر باشد، می توانیم تصمیم مناسب را اتخاذ کنیم.
هر چه این اختلاف بیشتر باشد، نشان از رد شدن فرض صفر و پشتیبانی بیشتر فرضیه جایگزین خواهد بود. t-statistics همان آماره در نظر گرفته شده برای آزمایش است که مقدار آن را با مقدار میانگین جامعه مقایسه خواهیم کرد. در این مثال، t-statistics میانگین دفعاتی است که از ده بار، برگ ها درست حدس زده شده اند.
اختلاف بین این عدد میانگین به دست آمده و عدد متناظر میانگین در جامعه معمولی، مبنایی برای سنجش فرضیه صفر خواهد بود. هر چه این اختلاف بیشتر باشد، نشانگر این است که احتمال درست بودن فرضیه جایگزین، بیشتر است. (به تفاضل بین این دو میانگین، یعنی میانگین نمونه های ازمایش با نمونه های دنیای واقعی ، بخش بر انحراف معیار استاندارد، t-value گفته میشود که این مقدار هم می تواند مبنای تصمیم ما باشد و هر چه عدد بزرگتری را نشان دهد، فرضیه جایگزین را تقویت خواهد کرد.)
هنگام بررسی نتایج آزمایش، چهار حالت ممکن است پیش بیاید که در دو حالت آن، جواب بدست آمده با جواب واقعی متفاوت است و جزء خطاهای این روش در نظر گرفته میشود:
نتیجه آزمون بیانگر این است که جان و ایزاک نهان بین هستند. آنها در حقیقت هم نهان بین هستند
نتیجه آزمون بیانگر این است که جان و ایزاک، نهان بین نیستند. آنها در واقعیت هم نهان بین نیستند آزمایش فرضیه پژوهش
نتیجه آزمون بیانگر این است که جان و ایزاک، نهان بین هستند، آنها در حقیقت نهان بین نیستند (False Positive)
نتیجه آزمون بیانگر این است که جان و ازاک، نهان بین نیستند، آنها در حقیقت نهان بین هستند (False Negative)
با نتیجه حالت یک و دو ، که مشکلی نداریم و آزمون ما به درستی ، عمل کرده است .اما
حالت ۳، فرضیه صفر را رد می کند در حالی که این فرضیه برقرار است. این امر یک False Positive است. به این نوع خطا، خطای نوع یک (Type I Error) می گوییم. ( you falsely reject the (true) null hypothesis)
حالت ۴، فرضیه صفر را می پذیرد در حالی که در عمل، این فرضیه برقرار نیست. این امر یک False Negative است. به این نوع خطا، خطای نوع دو (Type II Error) می گوییم. (incorrectly retaining a false null hypothesis)
دقت کنید که عبارت False Positive یا درست نما و عبارت False Negative یا نادرست نما با مبنا قرار دادن فرضیه جایگزین، معنا می یابند . درست نما در اینجا یعنی فرضیه جایگزین را پذیرفته ایم و آنرا درست قلمداد کرده ایم، درصورتیکه فرضیه صفر درست است و بالعکس، در خطای نوع دو، ما با نادرست نما مواجه هستیم . یعنی فرضیه جایگزین را نادرست فرض کرده ایم در صورتیکه فرضیه صفر باید رد شود.
نوع خطای یک، برای حالتی است که اشتباها فرضیه صفر را رد کرده ایم و خطای نوع دو، هم زمانی است که اشتباها آنرا پذیرفته ایم.
همانطور که مشاهده می کنید، نتایج به دست آمده ممکن است با واقعیت متفاوت باشد و نمی توان با اطمینان صد در صد، فرضیه صفر را رد کرده یا آنرا تایید کنیم. بنابراین هنگام اعلام نتایج باید درصد اطمینان خود به نتایج را هم بیان کنیم. این درصد اطمینان را «سطح اطمینان» می نامیم و آنرا با آلفا α نمایش می دهیم
آلفا ، احتمال رخداد خطای نوع یک است یعنی احتمال اینکه ما فرض صفر را رد کنیم در صورتیکه در واقعیت، این فرض صحیح باشد و چون این عدد، یک احتمال است عددی بین صفر و یک خواهد بود. سطح اطمینان، حاصل تفریق یک منهای آلفا خواهد بود (به صورت درصد). مثلاً اگر آلفا، ۰٫۰۵ باشد، سطح اطمینان ما ۹۵ درصد خواهد بود.
برای کارهایی که چندان اهمیت حیاتی ندارد، مقدار معمول سطح اطمینان، ۹۵ درصد است اما برای کارهایی که اهمیت فراوان داشته ، دقت زیادی نیاز دارد سطح اطمینان ما باید حدود ۹۹ درصد باشد یعنی احتمال اینکه یک فرضیه درست را رد کرده باشیم، زیر یک درصد باشد. مقادیر معمول برای آلفا، ۰٫۰۱، ۰٫۰۵ و ۰٫۱ است.
از طرفی، داده های آزمون، ممکن است شانسی به دست آمده باشند. مثلاً جان و ایزاک، به طور شانسی ۸ مورد از ۱۰ را درست گفته باشند. در این حالت، به اشتباه، فرضیه جایگزین را تایید کرده ایم. بنابراین میزان شانسی بودن نتایج، با فرض درست بودن نظریه صفر هم باید در نتیجه گیری ما، مشخص شود. به این مقدار، P-Value می گوئیم.
مفهوم p-value را با شکل توضیح می دهیم. اگر شکل زیر را تابع توزیع احتمال حدس های مختلف افراد در بازی نهان بینی بدانیم، مقدار قله، متناظر با عدد ۶ که میانگین جامعه آماری در نظر گرفته ایم، خواهد بود. هنگام آزمودن افراد مختلف برای حدس زدن مقدار برگ متناظر با یک کارت، اعداد کمتر و بیشتر از این میانگین را هم شاهد خواهیم بود اما از یک عدد به بعد، حدس می زنیم که تفاوت فرد آزمون دهنده با سایر افراد معنا دار خواهد بود و این فرد، دارای استعداد خاصی به نظر می رسد. به این عدد، مقدار حیاتی می گوییم. ( Critical value ). همانطور که در شکل زیر که توزیع حدس های مختلف افراد معمولی جامعه است، مشاهده می کنید، ممکن است که این فرد جزء معدود افراد خوش شانسی باشد که در ناحیه نارنجی رنگ قرار می گیرند و واقعاً تفاوت معناداری با بقیه افراد ندارد اما به دلیل بالا بودن میانگین عدد حدسیات او، جزء افراد نهان بین یا جادوگر در نظر گرفته شده است.
بنابراین، مساحت ناحیه نارنجی رنگ مشخص کننده درصد معدود افراد خوش شانسی است که از مقدار حیاتی آزمون، عدد بیشتری را تصادفاً درست حدس زده اند و به همین دلیل، باعث رد فرضیه صفر شده اند.
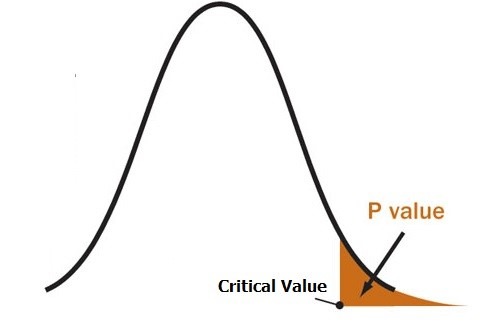
نکته مهم در مورد P-value این است که این مقدار، کاملاً به تعداد نمونه های گرفته شده، بستگی دارد و هر چه آزمون را بیشتر تکرار کنیم، مقدار محاسبه شده برای آن، کمتر خواهد شد . یعنی شانس اشتباه یا تصادفی بودن نتایج، کم خواهد شد و با اطمینان بیشتری، خواهیم توانست فرضیه صفر را رد یا تایید کنیم. همانطور که در شکل زیر مشاهده می کنید، هر چه تعداد نمونه ها بیشتر باشد، نمودار توزیع جواب ها به توزیع نرمال نزدیک تر میشود و با یک بازه اطمینان ثابت، مقدار P-Value یا مساحت سطح نمودار بعد از مقدار حیاتی، کاهش می یابد.
در تفسیر نتایج آزمون، اگر عدد میانگین به دست آمده از عدد حیاتی یا آستانه قبول فرضیه صفر، فراتر رود، برای رد کردن فرضیه صفر به مقدار P-Value نگاه خواهیم کرد. اگر این مقدار، از آلفا که میزان مورد قبول شانسی بودن رد شدن فرضیه صفر را بیان میکند، کمتر باشد، با سطح اطمینان مشخص شده اعلام می کنیم که فرضیه صفر برقرار نیست اما اگر مقدار P-Value بیشتر از مقدار آلفا باشد، نمیتوانیم فرضیه صفر را رد کنیم و ممکن است که این فرضیه برقرار باشد. آزمایش فرضیه پژوهش
جداول توزیع مقادیر P-Value سطح اطمینان و نیز درجه آزادی (تعداد نمونه ها – یک) در کتابها و سایتهای آماری موجود است که می توانید برای ارزیابی نتایج خود به آنها مراجعه کنید. مثلاً اگر تعداد نمونه های شما، ۲۰ و سطح اطمینان مد نظر شما، ۹۵ درصد باشد، مقدار P-Value را از جداول فوق، می توانید استخراج کرده و بر مبنای آن، قضاوت نهایی را انجام دهید.
البته در کتابها و نرم افزارهای آماری، آزمون فرضیه یک طرفه و دوطرفه داریم که در شکل زیر تشریح شده است. اگر فقط بر اساس یک مقدار بخواهیم تصمیم بگیریم، مشابه با این مثال که بر اساس عدد ۸، تصمیم خواهیم گرفت، آزمون فرضیه یک طرفه خواهیم داشت. اما اگر بر اساس کوچکتر بودن از یک عدد خاص و یا بزرگتر بودن از عددی دیگر، نظریه صفر را رد کنیم، آزمایش فرضیه دوطرفه خواهیم داشت.
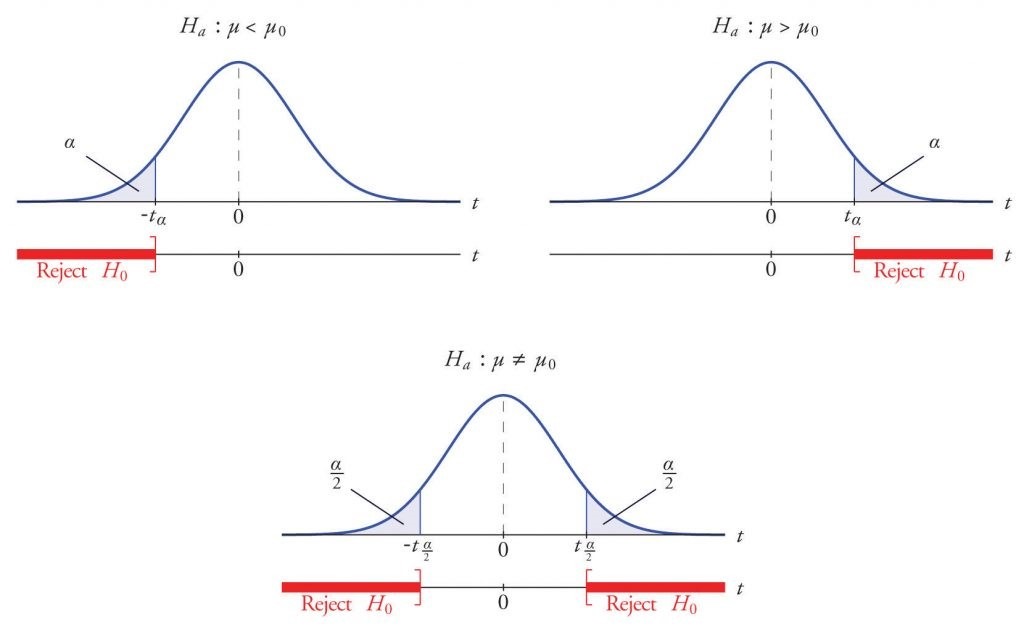
برای بازی نهان بینی، تصمیم میگیریم که اگر یک بازیکن، بیشتر از ۸ بار را درست حدس بزند، فرضیه جایگزین تایید و فرضیه صفر رد شود یعنی مقدار حیاتی ما عدد ۸ خواهد بود. از طرفی چون این مساله، یک مساله خیلی مهم در زندگی بشری نیست، مقدار آلفا را ۰٫۵ (یعنی سطح اطمینان ۹۵ درصد) در نظر خواهیم گرفت. آزمایش فرضیه پژوهش
گام پنجم : انجام آزمون
در این گام، آزمایش را به تعداد لازم تکرار کرده و در هر مرحله، نتایج را یادداشت می کنیم. در این مثال، کارتها را به کرات به جان و ایزاک نشان می دهیم و از آنها می خواهیم که برگ متناظر با هر کارت را حدس بزنند. میانگین هر ده بار نمایش را محاسبه و نهایتاً میانگین کل را برای هر شخص، به دست می آوریم. نتایج از قرار زیر است:
جان:
t-statistics :8
p-value=0.1
ایزاک:
t-statistics :9
p-value=0.01
همانطور که مشاهده می کنید مقدار P-Value برای ایزاک کمتر شده است که نشان از این دارد که آزمایشات را برای ایزاک به تعداد بیشتری تکرار کرده ایم.
گام ششم : ارزیابی نتایج
با توجه به مقادیر به دست آمده درباره جان و ایزاک می توانیم نتایج زیر را مشاهده کنیم:
جان:
جان به طور میانگین، هشت کارت را صحیح حدس زده است که از مقدار میانگین یک فرد معمولی بیشتر است.
مقدار P-Value برابر ۰٫۱ است که نشان میدهد ممکن است ۱۰ درصد، احتمال شانسی بودن نتایج وجود داشته باشد. این عدد، کمی بالاست.
آلفا برابر عدد ۰٫۰۵ است که آنرا ۵ درصد در نظر میگیریم.
P-Value از میزان مجاز شانسی بودن نتایج (سطح α) بیشتر شده است
ایزاک:
ایزاک به طور میانگین، ۹ باز از ده بار را درست حدس زده است. این عدد از میانگین جامعه بیشتر است
مقدار P-Value برابر ۰٫۰۱ است . بنابراین احتمال رخداد نتیجه اشتباه در تحلیل نهایی تنها یک درصد است.
آلفا برابر ۰٫۰۵ است که آنرا جهت مقایسه با P-Value ، پنج درصد در نظر می گیریم.
مقدار P-Value کمتر از آلفا است. آزمایش فرضیه پژوهش
گام هفتم : نتیجه گیری
با توجه به مشاهدات فوق نتایج زیر از این آزمون به دست خواهند آمد:
جان:
هر چند میزان حدسیات او از میزان میانگین جامعه بیشتر است اما چون میزان P-Value بیشتر از مقدار آلفا یا همان میزان مجاز شانسی بودن نتایج است، بنابراین خواهیم داشت:
شواهد کافی برای رد فرضیه صفر وجود ندارد. بنابراین این فرضیه هنوز پابرجاست و نمی توانیم با اطمینان بگوییم که جان ، نهان بین است.
ایزاک : با توجه به کمتر بودن P-Value از سطح آلفا، خواهیم داشت
شواهد کافی برای رد فرضیه صفر وجود دارد. بنابراین، فرضیه صفر رد شده و فرضیه جایگزین یعنی نهان بین بودن ایزاک، پذیرفته می شود.
دقت کنید که در مورد جان، نه می توانیم بگوییم که او جادوگر است و نه می توانیم با اطمینان بگوییم که او، یک فرد عادی است. بلکه باید آزمون های بیشتری انجام دهیم تا یا فرضیه صفر رد شده و یا مورد پذیرش قرار گیرد.
سخن آخر
آزمایش فرضیه یکی از مفاهیم کلیدی در علم یادگیری ماشین است و بسیاری از روشهای این علم، از آن برای ارزیابی نتایج خود استفاده می کنند. در ادامه این مباحث آموزشی ، به این موضوع بیشتر خواهیم پرداخت.
منبع: https://towardsdatascience.com