

سبد خرید من (0 )
انجام مدل تحلیل مسیر به روش سنتی در spss
- 8 آذر, 1400
- AMOS

انجام مدل تحلیل مسیر به روش سنتی در spss
انجام مدل تحلیل مسیر به روش سنتی در spss
فصل اول انجام مدل تحلیل مسیر به روش سنتی در spss
انجام مدل تحلیل مسیر به روش سنتی
با استفاده از روش های : ۱. قابلیت اعتماد ۲. تحلیل عامل و ۳. رگرسیون خطی
در نرم افزار spss
مقدمه
قبل از شروع آموزش نرم افزار آموس که از جلسه دوم آغاز میشود به نظر رسید در جلسه اول مروری بر انجام یک مدل تحلیل مسیر با روش سنتی (قبل از رایج شدن کاربرد دو نرم افزار آموس و لیزرل) داشته باشیم. در روش سنتی با استفاده از نرم افزار آماری spss و استفاده از سه دستور مهم:
1قابلیت اعتماد ۲. تحلیل عامل و ۳. رگرسیون خطی به ارائه یک مدل تحلیل مسیر میپردازیم . انجام مدل تحلیل مسیر به روش سنتی در spss
1.شروع عملیات
برای شروع کار ابتدا داده های خود را در نرم افزار spss فراخوانی می کنیم ،فایل داده ها (رضایت ۷۰) نام دارد به عنوان تحقیق (عوامل موثر بر رضایت شغلی) است. همانطور که در تصویر یک و دو میبینید،سازه های تشکیل دهنده متغیرهای این مدل مشخص شده اند.
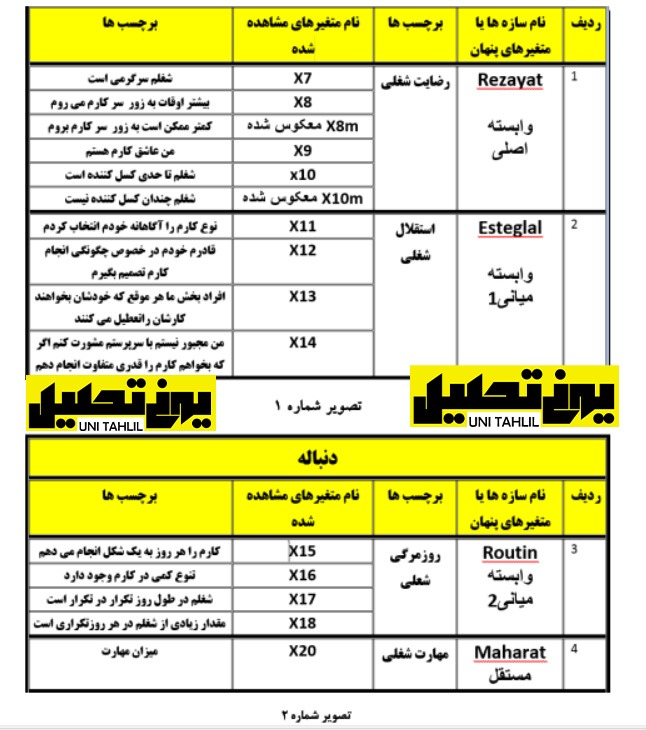
رضایت شغلی به عنوان متغیر وابسته ساز های است که از چهار متغیر مشاهده شده (x7’x8,9xو,x10) ساخته می شود. در این جدول مشاهده می گردد که در میان ۴ گویه فوق ، گویه های x9و x7 مثبت تلقی می شوند گویه های مثبت در سازه فوق گویه هایی هستند که نمره بیشتر در آن گوی دار بر رضایت شغلی بیشتر است و برعکس دو گویه x8 و x10 دو گویه منفی نامیده می شوند،گویه های منفی نیز گویه هایی هستند که نمره بیشتر در آنها دال بر رضایت شغلی کمتر است ؛ بنابراین سازه رضایت شغلی متشکل از دو گویه مثبت و دو گویه منفی هستند ، به دلیل این ناهمگونی، قابلیت اعتماد (reliability) این چهار گویه را محاسبه میکنیم . قابلیت اعتماد به ما نشان میدهد که تا چه اندازه میتوان این چهار گویه را برای سنجش یک متغیر واحد (رضایت) به کار برد. برای این منظور در ابتدای امر باید دو گویه x8 و x10 را معکوس کرده تا هم جهت با دو گویه مثبت دیگر سازماندهی شوند. همانطور که در تصویر یک هم دیده می شود،این دو گویه معکوس شده با عنوان x8m و x10m مشخص شده است.
پس از مثبت نمودن گویه های منفی گویه های x7 ، x8m ، x9 و x10 را وارد دستور قابلیت اعتماد می کنید تا مشخص گردد قابلیت اعتماد در مورد همسازی این گویه ها در سنجش میزان رضایت چه اندازه است. بر این اساس اگر قابلیت اعتماد به ما اجازه ادامه کار را داد آنگاه می توانیم با جمع چهار گوشه فوق (با دستور record یا کد گذاری مجدد) سفره ای به نام Rezayat و با برچسب رضایت شغلی بسازیم.
در مثال فوق سازه Rezayat وابسته اصلی است. باید به این نکته توجه داشت که ما در هر تحقیق بیش از یک وابسته اصلی نداریم. در کنار وابسته اصلی دو سازه دیگر داریم با نام وابسته میانی یک و دو. سازه وابسته میانی یک با نام Esteglal و برچسب استقلال شغلی است و متغیرهای مشاهده شده این ساز عبارت اند از : x11 ، x12 ، x13 و x14 با مشاهده برچسب های متغیرهای مشاهده شده بالا مشخص می گردد که متغیر ها همگی شکل مثبت دارند ( لذا نیاز به معکوس نمودن ندارند) یعنی نمره بیشتر در هر یک از این چهار متغیر دال بر استقلال شغلی بیشتری خواهد بود.
سازه وابسته میانی 2 نیز با نام Routin و بربسب (روزمرگی شغلی) مشخص گردیده و دارای متغیرهای مشاهده شده x15 x16 x17 وx18 است با مشاهده برچسب های متغیرهای مشاهده شده این سازه مشخص میگردد که متغیرهای وابسته میانی 2 برعکس متغیرهای وابسته میانی 1 همگی دارای بار منفی می باشند ازاین رو بجای معکوس نمودن متغیرها اسم سازه را معکوس مینماییم.
روزمرگی شغلی تغییر داده ایم در این سازه نمره بیشتر دال بر روزمرگی شغلی بیشتر و کم بودن تنوع شغلی است (شکل شماره 2 ). انجام مدل تحلیل مسیر به روش سنتی در spss
اما چهارمین سازه با نام مهارت و برچسب (مهاره شغلی) است و تنها یک متغیر مشاهده شده دارد و آن x20 و با برچسب (میزان مهارت) است مطابق جداول فوق مشخص میگردد که ما در مثال پیش رو سه دسته متغیر بیشتر نداریم (1)وابسته ارلی (2)وابسته میانی 1 و 2( 3 )مستقل
2 .تفاوت بین سه سازه (وابسته اصلی)، (وابسته میانی) و (مستقل) :
· وابسته اصلی سازه ای است که به سمت او فلش تحلیل مسیری پرتاب میشود ولی فلش تحلیل مسیری از آن صادر نمیشود .
· وابسته میانی در اینجا ما دو وابسته میانی داریم آنها سازه هایی هستند که هم فلش به سمت آنها پرتاب میشود و هم از آنها صادر میگردد .
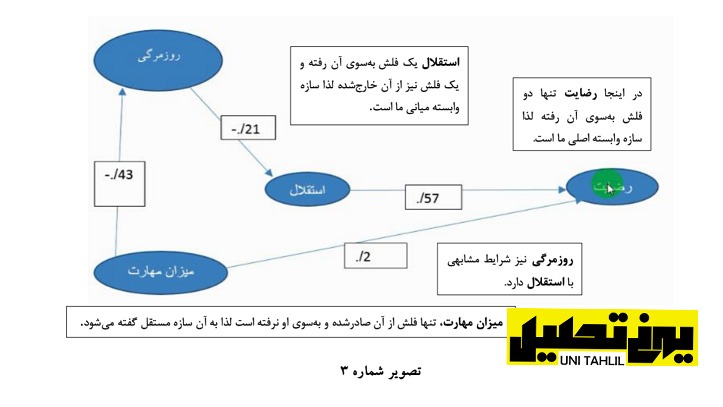
· سازه مستقل سازه ای است که تنها فلش را پرتاب میکند به عبارتی فلش تحلیل مسیری به سمت او پرتاب نمیشود درنهایت مدل تحلیل مسیری زیر از کار ما به دست می آید (تصویر شماره 3).
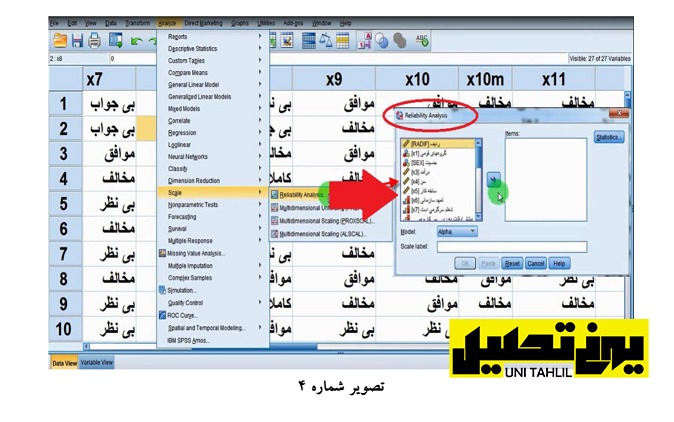
برای شروع کار ابتدا نرم افزار SPSS را باز میکنیم و در فایل بازشده تمام متغیرها از x7 تا x18 پدیدار میگردند . ازاین رو ابتدا بین x7 x8 x9 و x10 یک قابلیت اعتمادReliability)) میگیریم میخواهیم ببینیم که دستور Reliability به ما اجازه میدهد که چهار متغیر مذکور را با یکدیگر جمع بزنیم و جمع آن را یک سازه کنیم برای این کار با استفاده از بخش Analyze وارد بخش Scale شده و گزینه Reliability Analysis را میفشاریم (تصویر شماره 4 ).
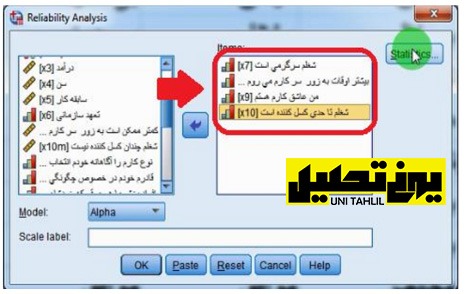
در پنجره به وجود آمده متغیرهای x7 x8 x9 و x10 را از ستون سمت چپ انتخاب کرده و توسط فلش واسط به ستون سمت راست (ستون Items )انتقال میدهیم (تصویر شماره 5 ) انجام مدل تحلیل مسیر به روش سنتی در spss
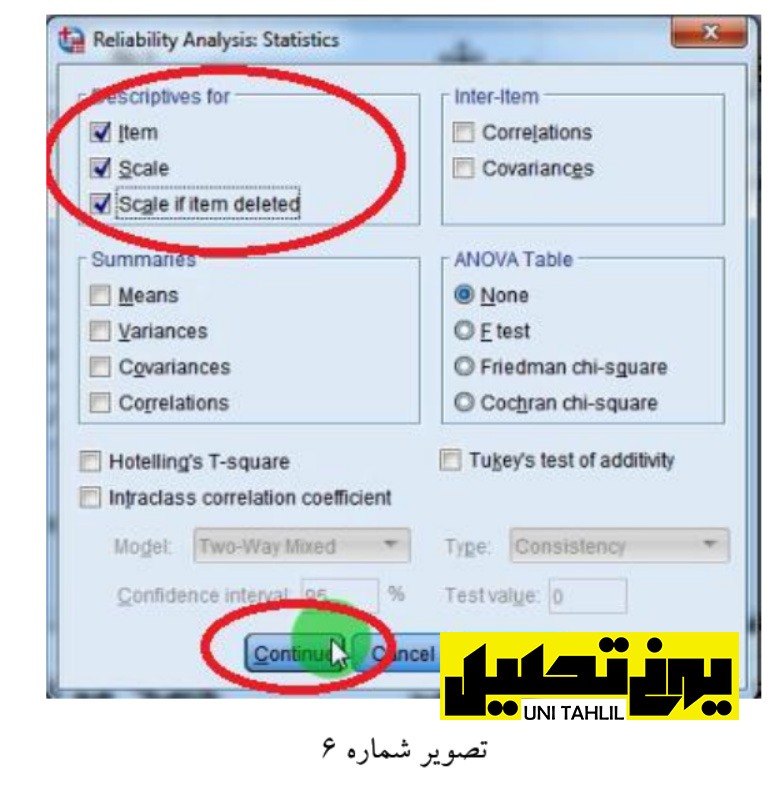
در ادامه بر روی دکمه Statistics (سمت راست پنجره) کلیک میکنیم به دنبال آن پنجره :Analysis Statistics Reliability پدیدار میگردد (تصویر شماره 6 ) در قسمت) for Descriptives آمارهای توصیفی برای( سه گزینه مشخص شده در تصویر شماره 6 را (آیتم مقیاس و مقیاس در وقتیکه یک آیتم یا گویه حذف شود) تیک میزنیم سپس دکمه Continue را میزنیم از پنجره قبلی نیز دکمه OK را میزنیم تا پنجرهای جدید نمودار گردد (تصویر شماره 6)
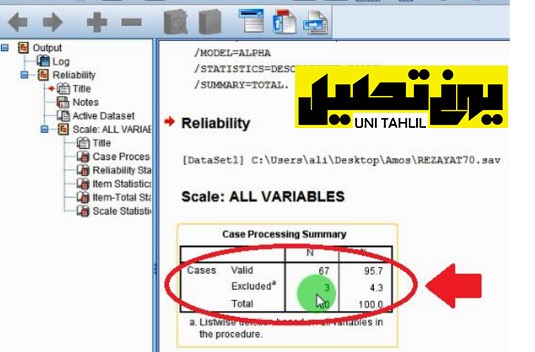
با کلیک بر دکمه ادامه پنجره جدید که حاوی آماره های Reliability است باز میشود که دربرگیرنده جداول مختلفی است نخستین جدول (مطابق تصویر شماره 7) گویای این امر است که آماره های مورد نظر مربوط به 67 مورد پرسشنامه مورداستفاده و 3 مورد پرسشنامه ای است که به دلیل نواقصی حذف گردیده است (تصویر شماره 7)
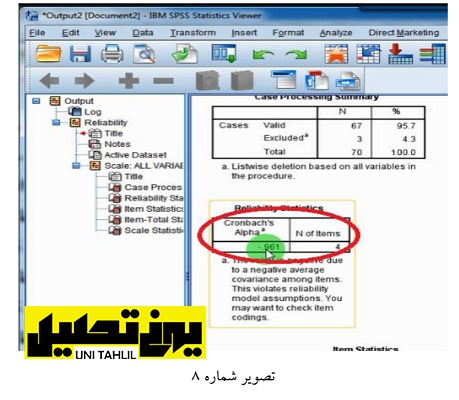
دومین جدول از پنجره مذکور جدول آلفای کروم باخ است که آماره آن 961/0 – است با توجه به آنکه مقدار مطلوب در این زمینه بالای 7/0 است منفی بودن این میزان فرآیند کار را دچار مشکل میکند بدین معنا که آلفای کرونباخ باید عددی مثبت باشد.(تصویر شماره 8)
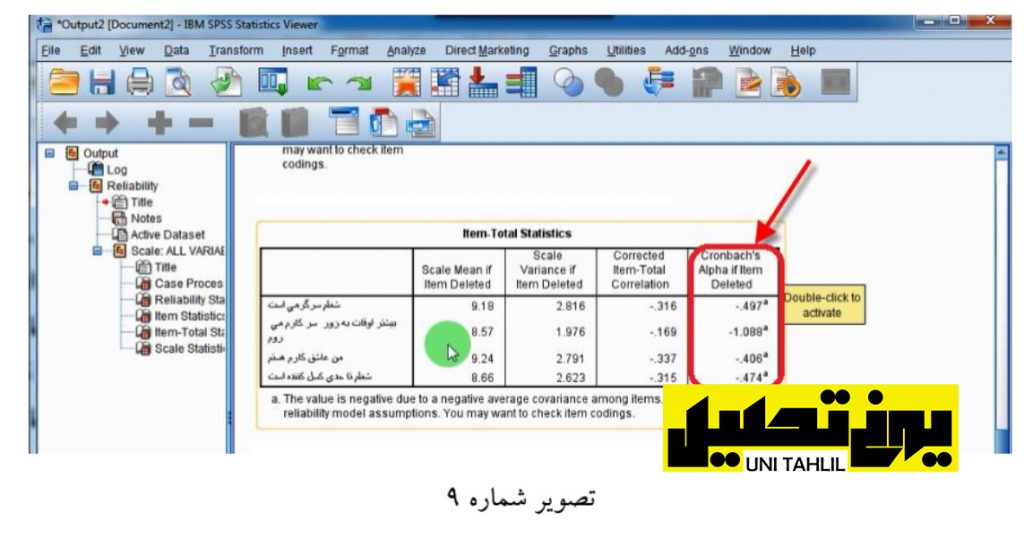
سومین جدول از پنجره مذکور جدول statistics Total-Items یا آماره های مربوط به گویه ها است در این جدول با بررسی آلفای کروم باخ گویه ها مشخص میشود که آلفای کروم باخ هر چهار گویه منفی است لذا به طور طبیعی نیز خروج هرکدام از این گویه ها سبب نمیشود که آلفا مثبت گردد برا که این منفی بودن همه بهار گویه را شامل میشود .(تصویر شماره 9)
برای اصلاح این مشکل میتوان به هم جهت نبودن گویه ها به طورکلی اشاره نمود برای حل این مشکل و مثبت نمودن گویه های منفی با زدن دکمه Data To Go در نوارابزار بالای نرم افزار به صفحه اصلی بازمیگردیم (تصویر شماره 10)
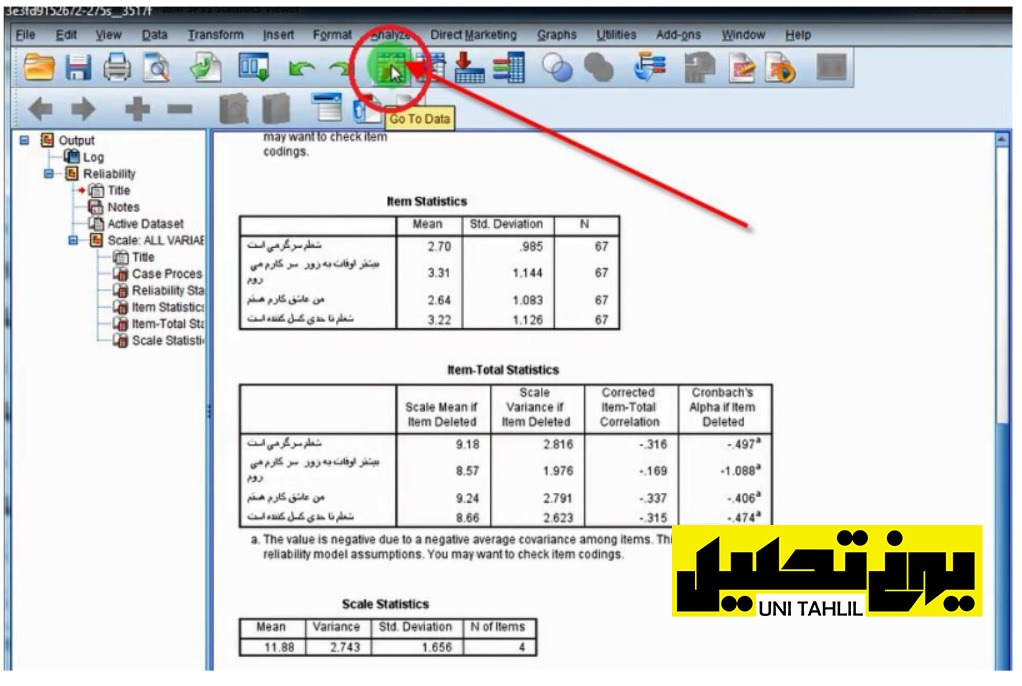
همانطور که در صفحات نخست توضیح داده شد از طریق دستور کدگذاری مجدد (Recode )برای گویه های x8 و x10 شکل معکوس آن را با نام های x8m و x10m ساخته ایم درنتیجه معکوس شدن این مقادیر نیزانها به شکل زیر نمایان میشوند (تصویر شماره 11 ) یعنی 1 به 5 2 به 4 3 به 3 4 به 2 و 5 به 1 تبدیل میشود
*لازم به ذکر است 0 یعنی بدون جواب بودن آن مقدار که در معکوس شدن همان عدد 0 باقی میماند.
بر این اساس مجدداً با رفتن به بخش Analyze Reliability / Scale / Analyze و کلیک بر روی آن پنجره ای جدید به همین نام ایجاد میکنیم (تصویر شماره 12 )
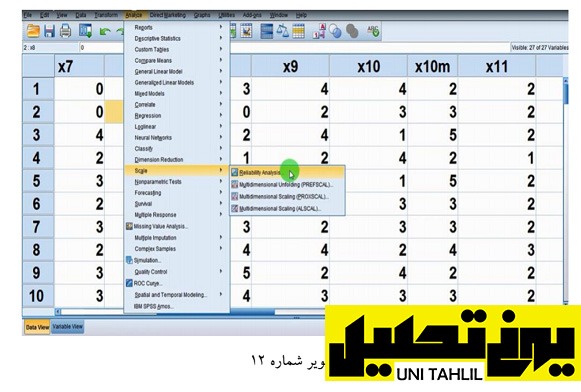
با باز شدن پنجره Reliability از ستون سمت چپ گویه های x7 x8 x9 و x10 را وارد ستون سمت راست مینماییم باید به خاطر داشت که انجام این کار برای سنجش میزان قابلیت اعتماد در این چهار گویه است (و نه گویه های معکوس شده) (تصویر شماره 13)
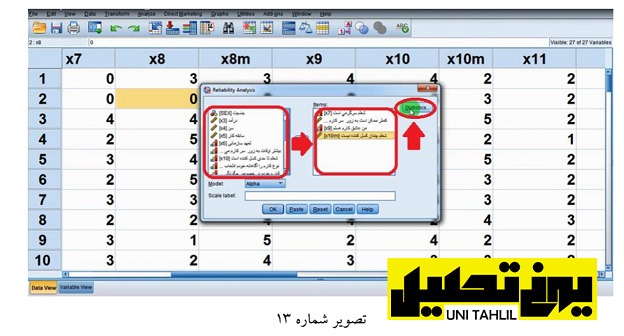
قبل از زدن OK با فشردن دکمه Statistics( تصویر شماره 13 ) وارد پنجره :Analysis Reliability Statistics شده و در قسمت) for Descriptives آمارهای توصیفی برای( سه گزینه ذیل آن را آیتم مقیاس موقعی که یک آیتم و گویه حذف شود تیک میزنیم سپس دکمه Continue را میزنیم و از پنجره قبلی نیز دکمه OK را میزنیم تا پنجره وروجی نمودار گردد پنجره جدید که حاوی آماره های Reliability است برعکس آمارهای جدول شماره 9 قبلی دارای آلفای کروم باخ مثبت 76 است؛ که این آماره گویای این موضوع است که ما میتوانیم این چهار گویه را باهم جمع بزنیم و از آن یک سازه بسازیم )تصویر شماره 14)
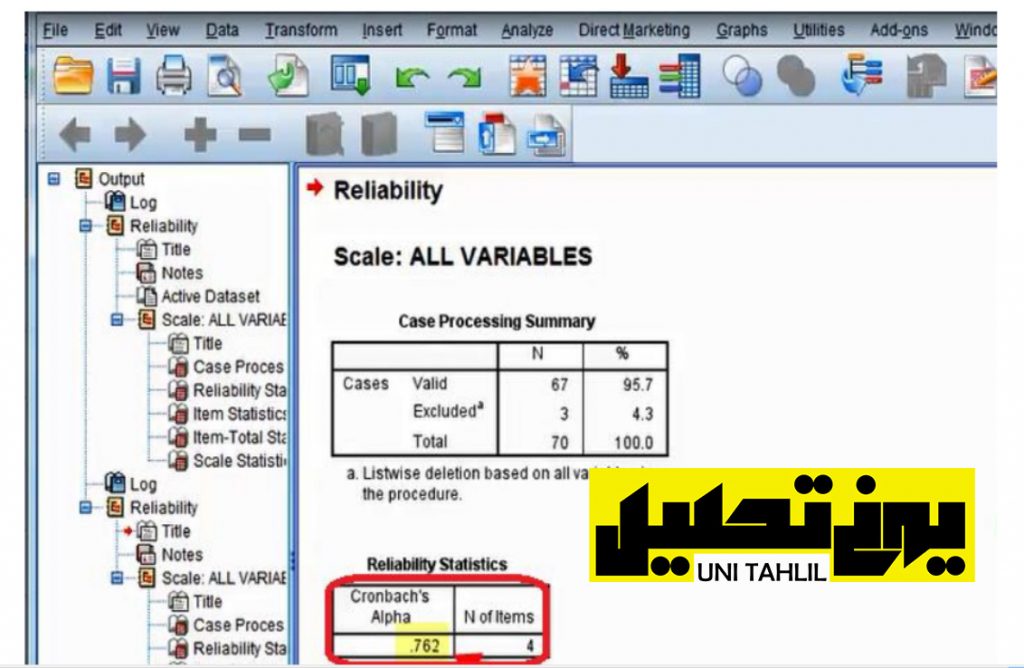
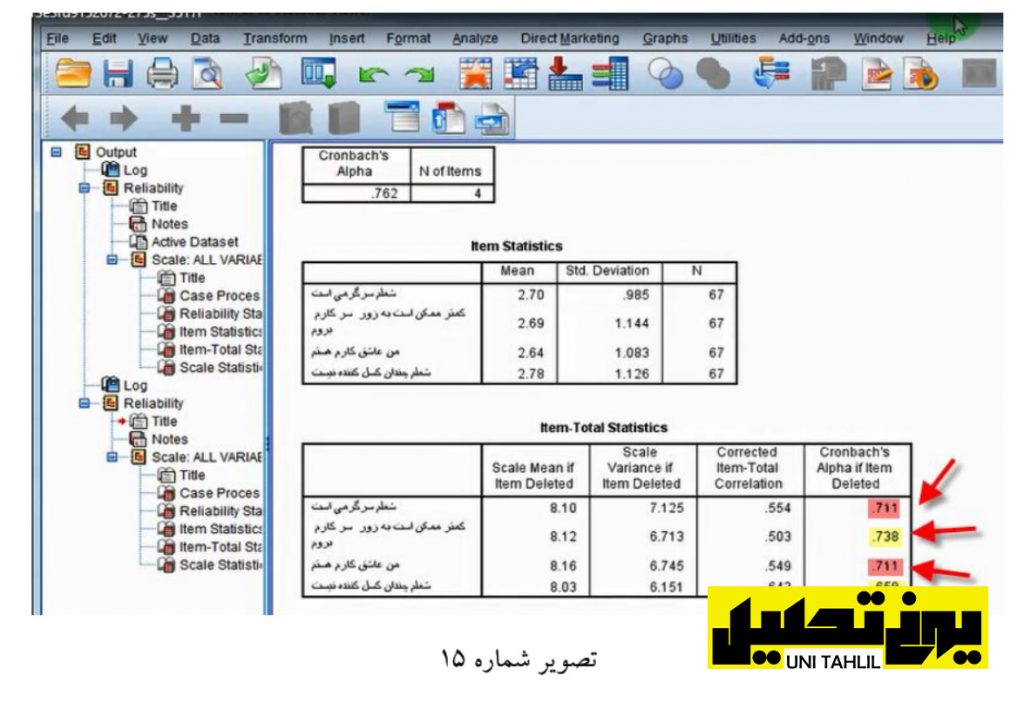
در جدول Statistics Total-Items که مربوط به آماره های گویه ها است اگر گویه (شغلم سرگرمی است) حذف شود آلفای کروم باخ کم میشود لذا این گویه نباید حذف شود گویه دیگر که (کمتر ممکن است به زور سرکارم بروم) اگر حذف شود آلفای کروم باخ از 76/0 به 74/0 تقلیل مییابد لذا این گویه نیز نباید حذف شود گویه سوم (من عاشق کارم هستم) نیز درصورتی که حذف شود آلفای کروم باخ کم میشود گویه چهارم (شغلم چندان کسل کننده نیست) هم اگر حذف شود آلفای کروم باخ به زیر 70/0 تقلیل پیدا میکند؛ بنابراین میتوان نتیجه گرفت که تمامی گویه ها مهم هستند زیرا با حذف آنها آلفا کروم باخ بهبود نمییابد و ما x8m x9 میتوانیم با جمع زدن چهار گویه x7 و m x10 سازهای با عنوان Rezayat و با بربسب رضایت شغلی بسازیم (تصویر شماره 15)
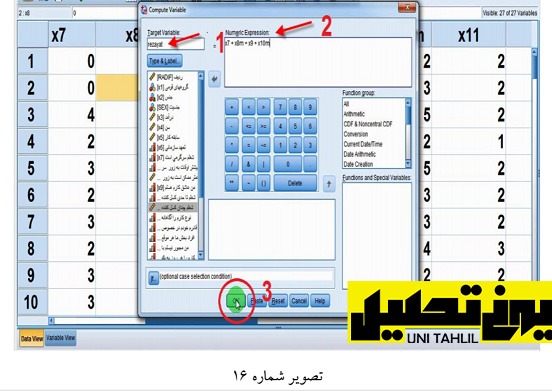
برای ساختن سازه رضایت شغلی از پنجره جدول بالا خارج میشویم و با آوردن مجدد پنجره اصلی SPSS برای ساختن شاخص با رفتن به بخش Transform و انتخاب گزینه Variable Compute( محاسبه متغیر جدید( پنجره ای جدید با همین نام باز میشود در پنجره بازشده در قسمتTarget: Variable اسم سازه را با عنوان rezayat تایپ مینماییم و در سمت راست پنجره قسمت Expression Numeric(فرمول عددی( فرمول مورد نظرر خود را تایپ مینماییم سپس دکمه OK را میزنیم )(تصویر شماره 16)
پس از اتمام این مرحله ستونی در داده های نرم افزار Spss به نام Rezayat ساخته میشود همانطور که در تصویر زیر دیده میشود و با بررسی داده ها مشخص میشود که دو مورد از داده ها بی جواب مانده اند که این دو مورد مواردی است که در یکی از چهار گویه جوابی نداشته است (جدول شماره 17 )باید دقت کرد که باید موارد بی جواب را حذف کنیم تا نتایج دقیق تری به دست آوریم.
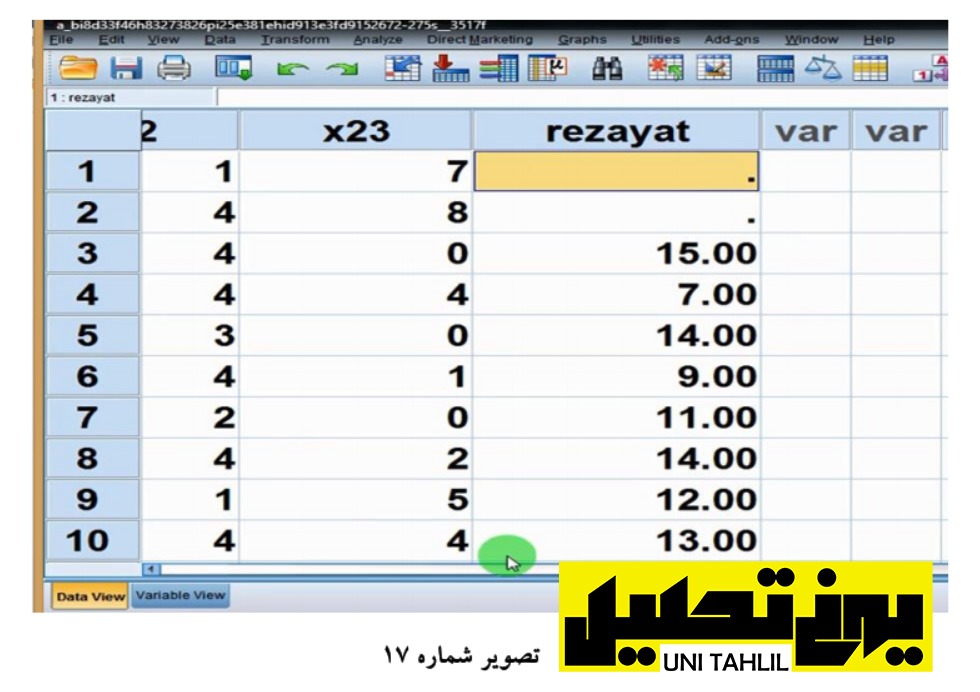
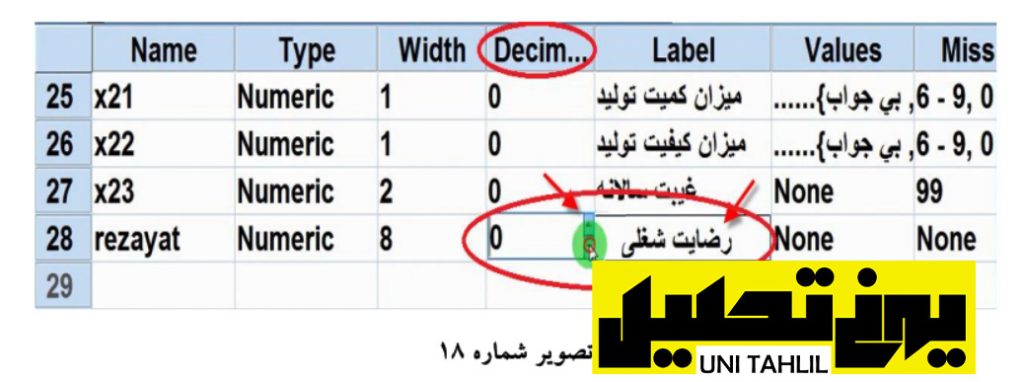
نکته دیگر آنکه همانطور که در تصویر 17 دیده میشود اعداد بخش رضایت دارای اعشارهای دو رقمی هستند برای حذف اعشار داده ها و رسیدن به یک عدد صحیح با رفتن به قسمت View Variable و پیدا کردن سطر rezayat از ستون Decimal با کلیک بر روی کادر به وسیله فلش کنار کادر عدد 2 را صفر مینماییم در ستون Label عنوان فارسی رضایت شغلی را مینویسیم(تصویر شماره 18 (‘
* لازم به ذکر است چون این متغیر فاصله ای شده مقادیر داخلی برچسب Label 9الزام ندارد
سپس با رفتن به قسمت View Data در نوارابزار پایین نرم افزار صفحه اصلی مشخص میگردد که اعشار داده ها حذف گردیده است در ادامه با ضبط داده ها به سراغ دو سازه بعدی که وابسته میانی 1 Esteglal و وابسته میانی 2 Routin است میرویم بر این اساس ما بر روی گویه های “x11 تا x18 “برنامه قابلیت اعتماد Reliability را اجرا میکنیم بدین ترتیب که همچون فرآیند قبل با استفاده از دستور Analyze مطابق دستور زیر گزینه…Analysis Reliability را انتخاب میکنیم تا پنجرهای به همین نام نمودار گردد در پنجره بازشده نیز ابتدا داده های محاسبات قبل را با استفاده از دستور Reset پاک و سپس گویه های x11 تا x18 را انتخاب و وارد کادر :Items مینماییم سپس با زدن دکمهstatistics پنجره statistics: Analysis Reliability پدیدار میگردد از آن پنجره نیز سه گزینه ذیل for Descriptives همچون روال قبلی تیک میزنیم سپس دکمه Continue را میزنیم از پنجره قبلی نیز دکمه OK را میزنیم تا پنجرهای جدید نمودار گردد
خروجی که از این جدول به دست می آید ابتدا گویای میزان آلفای کروم باخ گویه های x11 تا x18 است که بر اساس آماره های جدول Statistics Reliability به دست می آید برای موردقبول بودن این رابطه آلفای کروم باخ میبایست مثبت 70/0 به باال باشد که در این مورد همانطور که در تصویر 20 میبینید این میزان برابر شده است با مثبت 38/0 یعنی در شرایط فعلی نمیشود این 8 گویه را باهم جمع زد؛ اما با مشاهده آماره های جدول Statistics Total-Item مشخص میگردد با وروج هیچکدام از داده های x11 تا x18 وضعیت آلفای کروم باخ بهبود نمی یابد درنتیجه حذف هیچکدام نمیتواند شرایط این مقدار را بهبود بخشد (تصویر شماره 20 )لذا این 8 گویه را داخل تحلیل عامل میبریم تا مشخص شود به تعداد عامل برای ما درست میشود بر این اساس صفحه خروجی آماره ها را میبندیم.

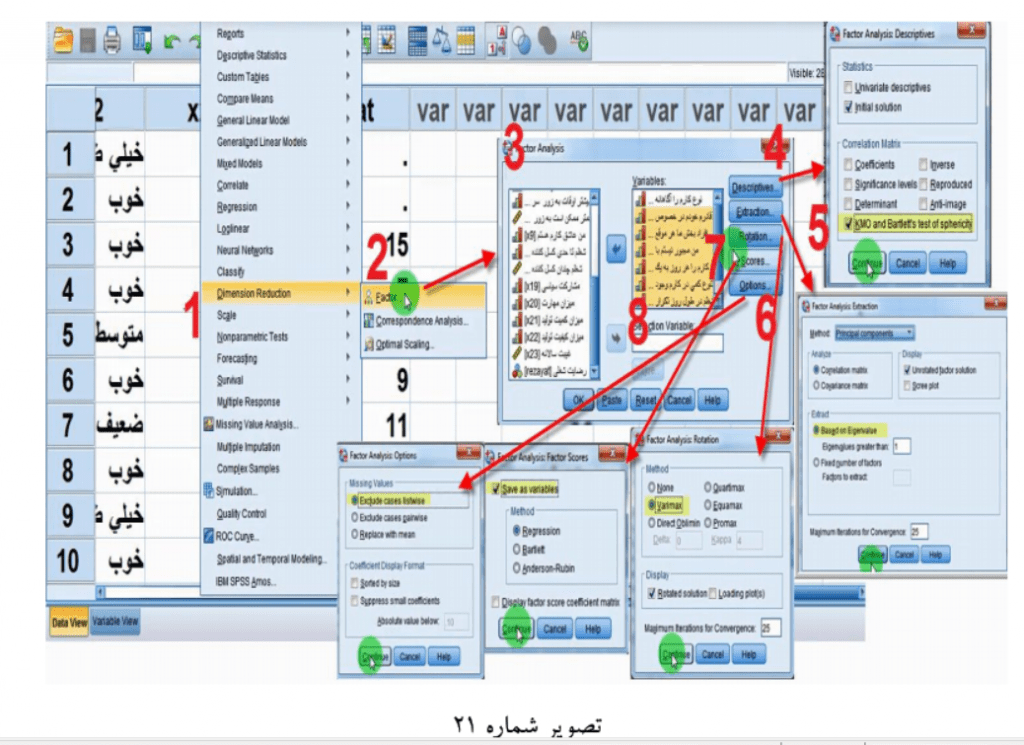
جهت تحلیل عامل با انتخاب گزینه Analyze از صفحه اصلی SPSS و دستور Reduction Dimension )کاهش ابعاد) و با انتخاب گزینه Factor پنجرهای به همین نام باز میشود در پنجره مذکور دو صفحه وجود دارد لذا ابتدا هشت گویه x11 تا x18 را به صفحه Variables منتقل میکنیم سپس ضروری است از بند گزینه مقابل این صفحه مواردی فعال یا اصطالحاً تیک زده شود بدین ترتیب که
· اولین دکمه »Descriptives »یا آماره های توصیفی را بازنموده و آخرین گزینه یعنی آماره ….KMO را تیک زده و فعال مینماییم سپس دکمه Continue را میزنیم
· دومین دکمه »Extraction »را بازنموده و از کادر Extract یا استخراجکن گزینه on Based Eigenvalue یا آماره ویژه را تیک زده و فعال مینماییم سپس دکمه Continue را میزنیم
· سومین دکمه »Rotation »با بروش را بازنموده و از میان گزینه های کادر Method گزینه Varimax یا واریانس حداکثر یعنی طوری دسته بندی کن این هشت گویه را که کمترین واریانس درون گروهی و بیشترین واریانس بین گروهی داشته باشند را تیک زده و فعال مینماییم سپس دکمه Continue را میزنیم
· چهارمین دکمه Scores یا نمرات را بازنموده و گزینه variables as Save یا ذخیره کن به عنوان متغیر جدید را انتخاب میکنیم در مورد روش محاسبه نمرات Method نیز در این کادر به صورت پیش فرض گزینه اول Regression تیک خورده آن را حفظ مینماییم بر این اساس دکمه Continue را میزنیم کاربرد این دستور یکی این است که ابتدا چهار گویه به نمره استاندارد تبدیل میشوند و دوم اینکه با ضریب یک همه را جمع نمیزند بلکه بسته به اهمیت آنها در یک رگرسیون ضرایب متفاوتی برای آنها استفاده میکند
· پنجمین و آخرین دکمه Options را بازنموده و مشاهده مینماییم که از میان گزینه های موجود برای روش حذف بی جوابها وود نرم افزار SPSS نخستین گزینه را به عنوان پیش فرض و با نام حذف موارد بی جواب به صورت فهرستی Listwise Cases Exclude انتخاب نموده است این گزینه در میان سایر گزینه ها گزینه بهتری است که نشان میدهد که موارد ضعیف را به صورت فهرستی کنار میگذارد در این دستور کسانی که حتی در یکی از این هشت گویه بی جواب داشته باشند کنار گذاشته میشوند به عبارت دیگر تنها کسانی میمانند که در همه هشت گویه جواب درست دارند (کلیه مراحل ذکرشده در تصویر شماره 21 آورده شده است ).
بدین ترتیب از صفحه قبل دکمه OK را میزنیم تا صفحه تحلیل آمارهزها بالا بیاید و خروجی کار مشخص گردد.
با آمدن صفحه Analysis Factor اولین جدول از این صفحه جدول Test s’Bartlett and KMO است Kaiser-Meyer-Olkin (مخفف KMO )
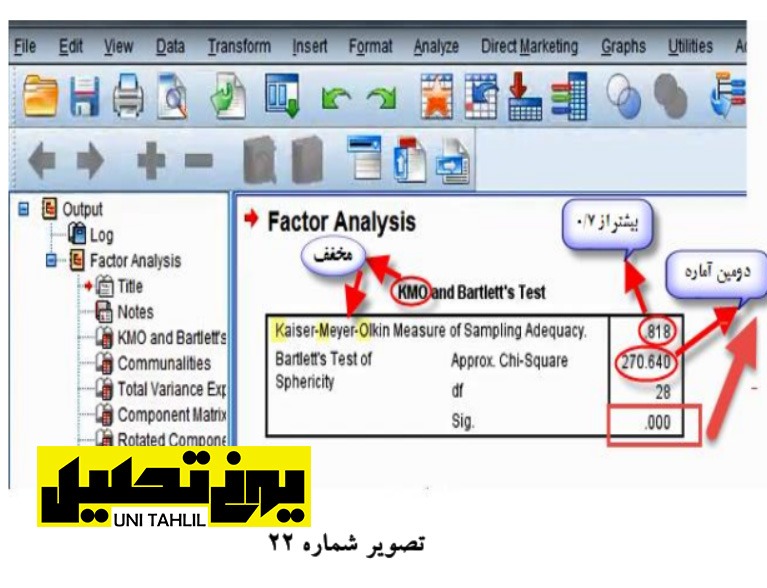
اولین آماره جدول مقیاسOlkin-Meyer-Kaiser برای بررسی این موضوع است که آیا اندازه نمونه ما برای ساختن تحلیل عامل مناسب است یا نه؟ درصورتی که مقدار این آماره بیش از 70/0 باشد نمونه ما مناسب است این میزان همانطور که تصویر باال مشاهده میشود 82/0 است لذا با این میزان نمونه ما میتوانیم تحلیل عامل درست کنیم
· دومین آماره جدول معرف همبستگی بین گویه ها است بدین معنا که آیا همبستگی بین گویه ها آنقدر بالا هست که ما بتوانیم از تحلیل عامل استفاده کنیم یا نه؟ لذا در این آماره کای اسکوئر تقریبی برآورده شده 270 بوده و سطح معنی داری آن Sig 000/0 است که چون کمتر از 05/0 و حتی کمتر از 01/0 است با اطمینان بالا 99 درصد اعلام میکنیم که همبستگی صفر بین گویه ها رد میشود و میزان همبستگی داخلی بین گویه ها برای ساختن تحلیل عامل کافی است (تصویر شماره 22).
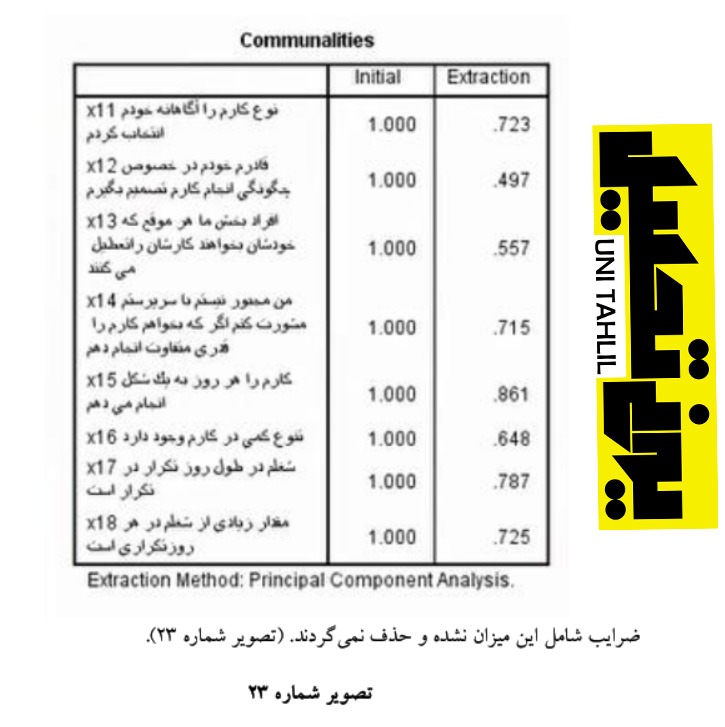
دومین جدول جدول اشتراک Communalities است در این جدول متغیرهای x11 تا x18 که در ستون Extraction آمده است نشان میدهند که هیچکدام از ضرایب را حذف نمیکنیم اگر ضریبی کمتر از 3/0 باشد اقدام به حذف آن میکنیم و همانطور که در شکل زیر میبینیم هیچکدام از ضرایب شامل این میزان نشده و حذف نمیگردند (تصویر شماره (23.
سومین جدول نشان دهنده کل واریانس تبیین شده Explained Variance Total است در این جدول هشت گویه داریم که به کمک آن هشت گروه در ستون Total ایجاد شده است در میان هشت گروه نیز تنها دو گروه مقادیر ویژه )Eigenvalues )آنها بالای یک است )میزان بالای عدد یک به معنی ساختن یک گویه مستقل است( و آن گروه اول و دوم است بر این اساس این هشت گویه بهوسیله دستور Analysis Factor به دو گروه دسته بندی شده اند (تصویر شماره 24)
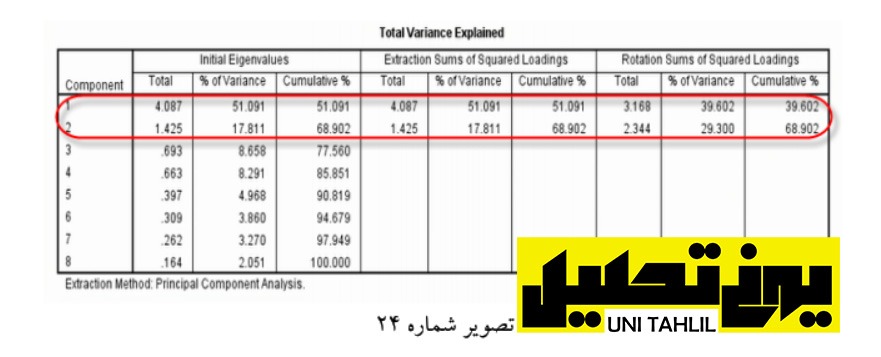
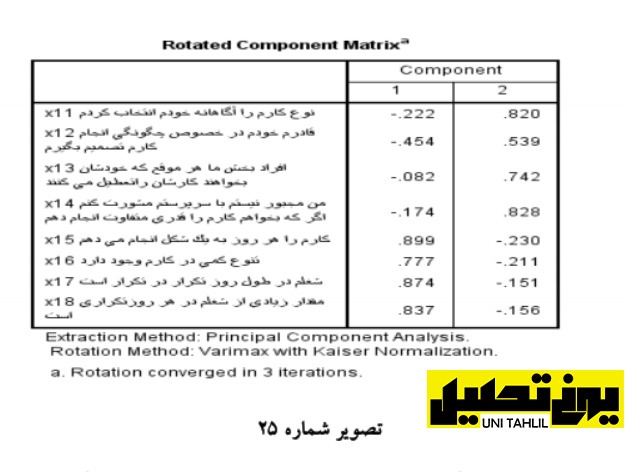
چهارمین جدول جدول ماتریس اجزاء Matrix Component قبل از اجرای عملیاه بروش Rotation است از این جدول عبور میکنیم چون خودمان از نرم افزار خواسته بودیم که عملیات چرخش را به روش واریماکس انجام دهد به طوری که همبستگی متغیرهای درون یک عامل به بیشترین حد خود و همبستگی بین متغیرهای دو عامل به پایین ترین حد خود برسد؛ بنابراین به پنجمین جدول با عنوان ماتریس اجزای بروش دادهشده Matrix Component Rotated میرسیم مطابق وروجی این جدول بهار گویه ستون 1 از x11 تا x14 منفی و چهار گویه بعدی از x15 تا x18 مثبت است با توجه به آنکه این همسانی در ستون 2 برعکس است میتوان نتیجه گرفت که گویه های این جدول را میتوان به صورت چهارتاچهارتا باهم جمع زد (تصویر شماره 25)؛ یعنی موارد مثبت با هم و موارد منفی با هم.
با خارج شدن از این صفحه مجدداً به صفحه صلی بازمیگردیم و مانند روالی که قبلا توضیح داده شد در صفحه اصلی با استفاده از گزینه Analyze و از طریق Scale و کلیک بر روی گزینه Analyze Reliability پنجره ای به همین نام باز میشود در این پنجره در قسمت :Items از هشت گویه x11 تا x18 مندرج بهار گویه x15 تا x18 را وارج نموده به پنجره دیگر منتقل مینماییم تا مجدداً به صورت مستقل مورد تحلیل قرار گیرند سپس با زدن دکمهStatistics پنجره Statistics: Analysis Reliability پدیدار میگردد از آن پنجره نیز سه گزینه ذیل for Descriptives( همچون روال قبلی تیک میزنیم سپس دکمه Continue را میزنیم از پنجره قبلی نیز دکمه OK را میزنیم تا پنجره خروجی جدید نمودار گردد.
در پنجره جدید »Viewer Statistics SPSS IBM »آماره قابلیت اعتماد یا آلفای ما 76/0 نشان داده میشود که میزان قابل قبولی است.
در جدول آماره های گویه-کل یا Statistics Total-Item با توجه به آنکه چهار گویه x11 تا x14 مورد تحلیل قرارگرفته است در ستون آور Deleted Item if Alpha s’Cronbach میزان آلفای شاخص کل درصورتی که هر گویه حذف شود آورده شده است به طور مثال مقدار آلفای شاخص کل 65/0 میشود اگر گویه x11 حذف شود یا اگر گویه x12 حذف شود میزان آلفای شاخص کل به 757/0 افزایش خواهد یافت با توجه به آنکه مطلوب است آلفای شاخص کل بالای 70/0 باشد نیازی به پاکسازی گویه ها نداریم فقط به ستون همبستگی اصلاح شده بین گویه –کل یا »Statistics Total-Item توجه میکنیم اگر همبستگی بین هر یک از گویه ها با شاخص کل کمتر از 3/0 بود در جهت حذف آن اقدام کرده و دوباره برنامه را اجرا میکنیم هیچکدام از گویه ها همبستگی کمتر از 3/0 با شاخص کل ندارند بنابراین تمامی گویه ها دارای اهمیت هستند و میتوان آنها را باهم جمع کرد (تصویر شماره 27).
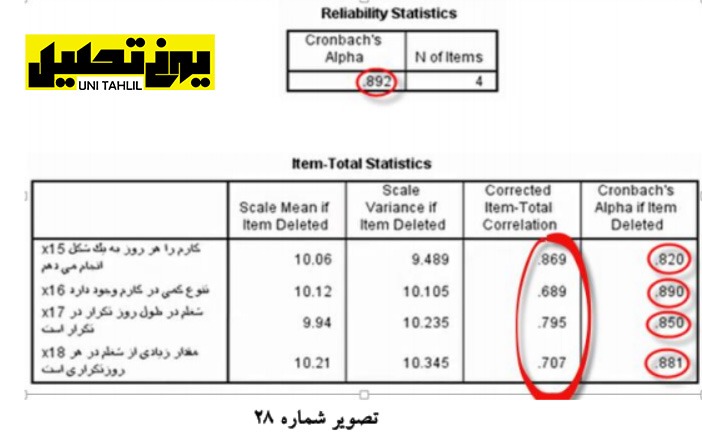
با خارج شدن از این صفحه مجدداً به صفحه اصلی بازمیگردیم در صفحه اصلی بار دیگر با استفاده از گزینه Analyze و دستور Scale و انتخاب گزینه Analyze Reliability این بار چهار گویه x11 تا x14 را خارج نموده و چهار گویه بعدی یعنی x15 تا x18 را وارد میکنیم میزان آماره آلفای این بند گویه این بار 9/0 است این میزان قابل قبول است )آلفای کرونباخ باید بالای 7/0 باشد( درنتیجه نیازی به مراجعه به ستون آخر نخواهد بود).
توضیح اینکه ستون آخر زمانی استفاده میشود که آلفای اولیه شاخص ما زیر 7/0 باشد در این صورت به ستون آخر مراجعه میکنیم تا ببینم با حذف کدام گویه ضعیف آلفای شاخص کل بیشتر بهبود مییابد بعد از یافتن آن گویه ضعیف و حذف آن و اجرای مجدد تحلیل قابلیت اعتماد دوباره موضوع را پی میگیریم تا به وضع مطلوب برسیم
در این شاخص هم به ستون ماقبل آخر توجه میکنیم که میزان همبستگی گویه ها با شاخص کل کمتر از 3/0 نباشد و همانطور که در تصویر میبینید این اتفاق رخ نداده است چرا که در این صورت یعنی چانچه موردی کمتر از 3/0 بود در جهت حذف آن و اجرای مجدد تحلیل قابلیت اعتماد اقدام میکنیم.
3 .ساختن دو شاخص استقالل شغلی و روزمرگی شغلی
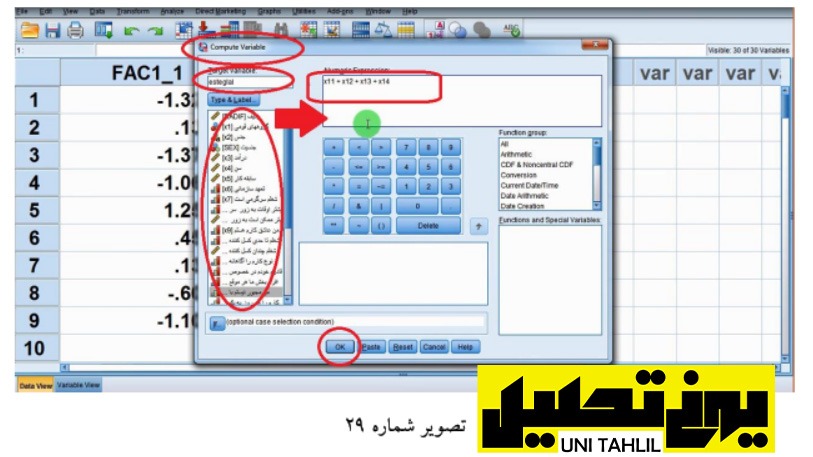
در این مرحله باید اقدام به ساختن دو شاخص جدید کنیم؛ برای ساخت دو شاخص استقلال و روتین ابتدا به بخش Transform از صفحه اصلی نرم افزار رفته و گزینه نخست Variable Compute را انتخاب مینماییم سپس با کلیک بر روی این گزینه پنجره ای با همین نام باز می شود در صورتی که از قبل اطلاعاتی در این پنجره موجود باشد گزینه Reset را کلیک نموده تا این بخش از نرم افزار از داده ها تخلیه گردد در ادامه در قسمت سمت چپ بالای پنجره Variable Compute در کادر کوچکی بنام Target Variable عنوان esteglal استقلال را تایپ مینماییم سپس در کادر سمت راست پنجره مذکور کادری تحت عنوان Expression Numeric قرار دارد که در آن گویه های موردنظر یعنی X14+X13+X12+X11 را از پنجره Label & Type وارد آن مینماییم و در ادامه دکمه OK را میزنیم (تصویر 29 )و به رفحه اصلی نرم افزار بازمیگردیم.
در صفحه اصلی نرم افزار مشاهده میگردد که در قسمت View Data ستونی با عنوان esteglal ایجاد گردیده است این بار با تکرار فرآیند قبل از طریق دستور Transform و گزینه Variable Compute و باز شدن پنجره ای به همین نام ابتدا با زدن گزینه Reset اقدام به تخلیه داده ها مینماییم بدین ترتیب با تایپn در کادر Variable Target و وارد نمودن گویه هایX18+X17+X16+X15 از کادر & Type Label به کادرExpression Numeric و زدن دکمه OK به رفحه اصلی نرم افزار مشاهده میگردد که ستونی دیگر بنامroutin ایجاد گردیده است )تصویر 30 (.
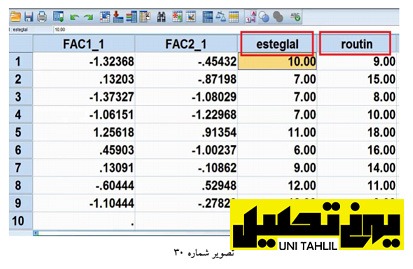
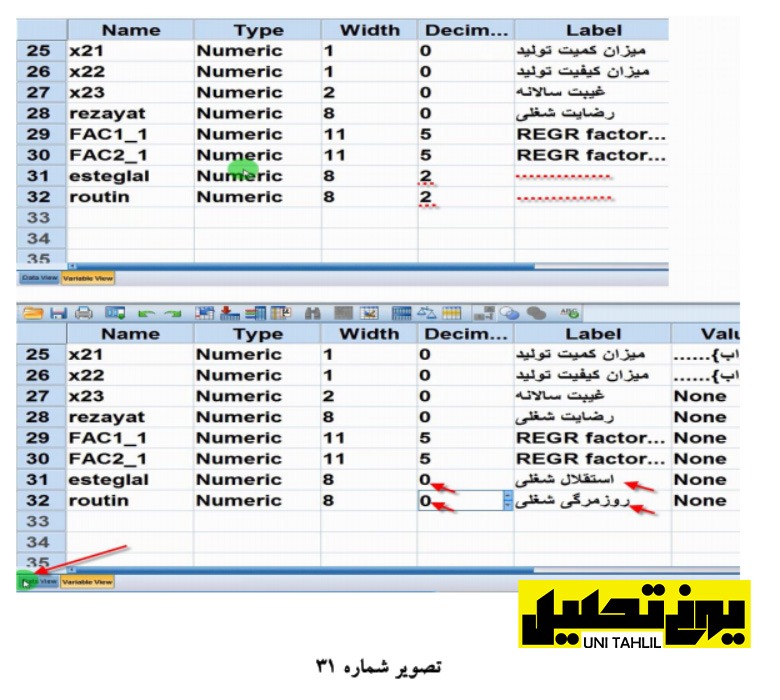
همانطور که در تصویر بالا دیده میشود پس ازاین اقدامات دو ستون به نام های روزمرگی و استقلال ایجاد میگردد جهت حذف اعشار و انتخاب برچسب فارسی برای دو ستون استقلال و روتین به پشت صحنه قسمت View Variable میرویم(تصویر شماره 31 )
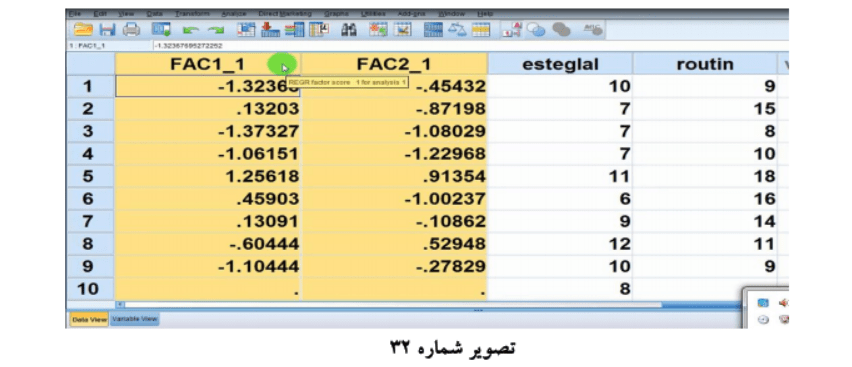
با تغییر برچسب ها و حذف اعشار بر روی View Data کلیک مینماییم با آمدن این صفحه در کنار ستون استقلال و روتین دو ستون دیگر که سازه هایی است که نرم افزار برای ما ساخته ارقام مندرج در آنها نیز ارقام اعشاری هستند نرم افزار برای سا خت این سازه ها دو کار انجام داده است 1 چهار گویه را تبدیل به نمره استاندار نموده است 2 هر گویه را با یک ضریب متفاوت ضرب و جمع نموده است؛ اما زمانی باید حتماً از این داده های استاندارد داده های این دو ستون استفاده کنیم که داده های ما یا از یک جنس نباشند مانند اینکه بروی رتبه ای باشند و بروی دیگر فاصله ای و یا اینکه اگر همه از یک جنس هستند دامنه شان یکسان نباشد مانند اینکه داده ها همه رتبه ای هستند ولی یکی رتبه ای 1-3 دیگری رتبه ای 1-5 و درحالی که گویه هایما همه رتبه ای هستند و دامنه نمرات آنان همه 1-5 است به همین خاطر در ستون استقلال و روتین به شکل ساده تری گویه ها را جمع نموده ایم با توجه به آنکه نیازی به عامل های استاندارد نداریم این دو ستون را حذف مینماییم (تصویر شماره 32 )
با حذف دو ستون مذکور سه سازه برای ما باقی میماند est eglal routin و rezayat یک سازه دیگر نیز داریم به نام مهارت که با x20 مشخص گردیده است لذا برای تبدیل آن به یک سازه با راست کلیک بر روی ستون و گرفتن Copy از آن به ستون خالی آخر در صفحه View Data رفته و با کلیک بر روی آن صفحه View Variable نمودار میگردد بر این اساس با اسم گذاری نام متغیر جدید در این صفحه در قسمت Name بنام maharat سایر آیتم های آن را به ترتیب تکمیل می نماییم. انجام مدل تحلیل مسیر به روش سنتی در spss
در ادامه با بازگشت به صفحه View Data ستون maharat را انتخاب و دکمه paste را میزنیم در ادامه تمام آماره های ستون x20 در ستون جدید جای میگیرد بدین ترتیب در صفحه نرم افزار چهار سازه مشخص میشود: maharat و routin esteglal rezayat .
4 .اجرای رگرسیون چند متغیره
در ادامه با استفاده از رگرسیون به ادامه کار میپردازیم بر این اساس مجدداً به قسمت Analyze میرویم و با انتخاب گزینه Regression و کلیک بر روی گزینه Linear رگرسیون وطی پنجره ای نمودار میگردد با نام Regression Linea در بالای این پنجره دو کادر وجود دارد یکی Dependent که محل قرارگیری متغیر وابسته است و دیگری s Independent که محل قرارگیری سایر متغیرها است بر این اساس ابتدا متغیر وابسته ما که رضایت شغلی rezayat است را در کادر Dependent قرار میدهیم و بقیه متغیرها اعم از وابسته های میانی و مستقل را در کادر :(s(Independent جای میدهیم (تصویر شماره 34)
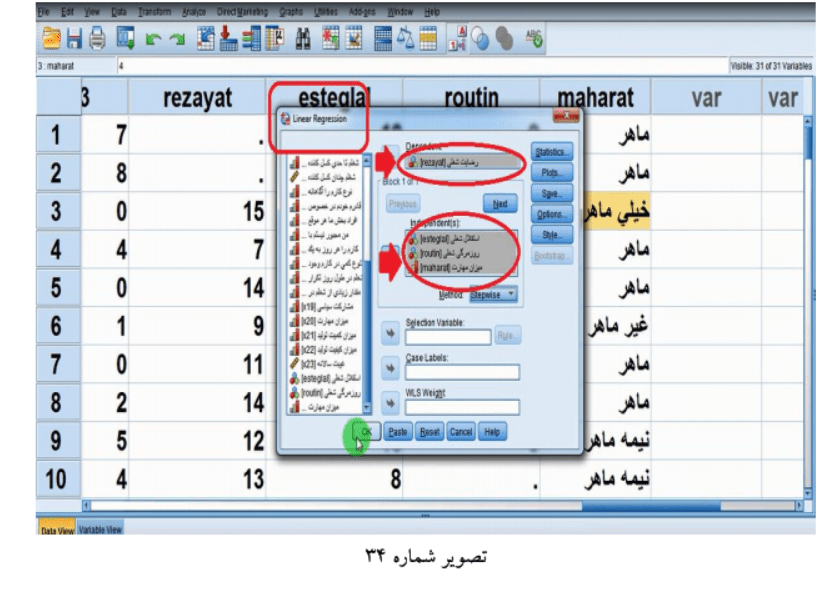
در پایین این کادر در تصویر 34 گزینه ای به نام روش Method قرار دارد این گزینه پنج آیتم دارد که هرکدام از گزینه ها برای شرایط متناسب با خود باید انتخاب شود بهترین شیوه برای وارد نمودن متغیرها به معادله رگرسیونی در اینجا Stepwise است Stepwise یعنی گام به گام یعنی ابتدا متغیرها را به ترتیب اهمیت هریک وارد کن و اگر با ورود متغیر جدیدتر متغیر قبلاً واردشده از اهمیتش کاسته شد آن را از معادله خارج کن این عمل ادامه پیدا میکند تا جایی که هیچ متغیر واردشده ای شرط اخراج نداشته باشد و هیچ متغیر بیرون مانده ای شرط ورود نداشته باشد P مربوط به شرط ورود 05/0 و P مربوط به شرط خروج 10/0 است پس ازاین انتخاب دکمه OK را میزنیم با زدن دکمه OK پنجره تحلیل آماره ها بنامViewer Statistics SPSS IBM نمودار میگردد اولین جدول از این پنجره جدول متغیرهای واردشده/ خارج شده یا Removed/Entered Variables است این جدول نشان میدهد هر سه متغیر ما به ترتیب اهمیت واردشده اند 1 -استقلال شغلی 2 -میزان مهارت و 3 -روزمرگی شغلی و با ورود متغیر جدید متغیرهای قبلاً واردشده اخراج نشده اند چون ستون سوم Removed Variables خالی است (تصویر شماره 35)
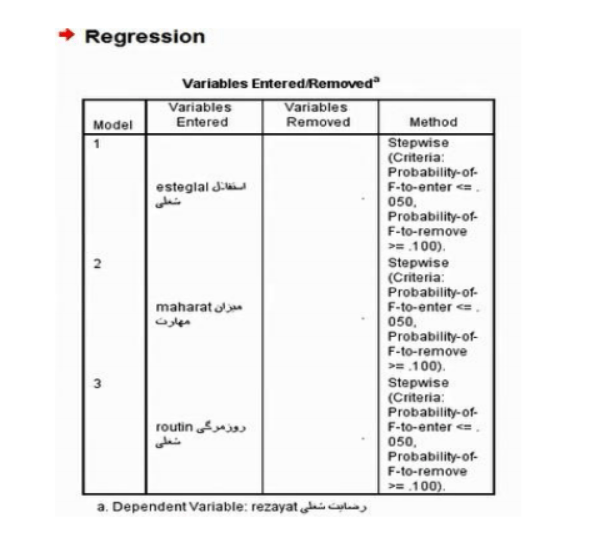
دومین جدول از این پنجره جدول Summary Model است در این جدول سومین یعنی آورین مرحله که R 0/8 میشود ما R میشود وارد 2 R 0/64 میشود 2 تعدیل شده ما 63/0 میشود؛ یعنی معادله رگرسیونی که این سه سازه در آن واردشده اند R یا همبستگی بندگانه اش که یکطرف این همبستگی رضایت و طرف 2 دیگرش سه تا سازه دیگر شامل استقلال روزمرگی و مهارت است 8/0 است R مساوی 647/0 نشان میدهد که این سه سازه توانسته اند حدود 65 درصد تغییرت متغیر رضایت شغلی را تبیین کنند البته اگر بخواهیم از 2 این نمونه 68 نفرِی در مورد جمعیت اصلی برآورد صحیح تری داشته باشیم باید از عدد R تعدیل شده برای این کار استفاده کنیم و بگوییم در جمعیت اصلی که این نمونه از آن استخراج شده است 63 دررد تغییرات رضایت شغلی وابسته به تغییراه این سه سازه است که میزان قابل توجهی است (تصویر شماره 36).
سومین جدول از این پنجره جدول تحلیل واریانس یا ANOVA است در این جدول نیز به ستون F و ستون Sig توجه میکنیم البته همیشه این F و Sig ردیف آخر است که باید مرکز توجه اصلی باشد برا که در میزان آور است که اثرات هر سه سازه در نظر گرفته شده و کاملترین مدل را به دست میدهد در این جدول میزان F و Sig ما قابل قبول است زیراSig ما زیر 1 صدم خطا و یا 99 درصد اطمینان است بون مرز پذیرش خطای آزمون F مساوی 05/0 است لذا میتوان فرض H0 را رد کرده و رگرسیون به دست آمده را پذیرفت )تصویر شماره 37)
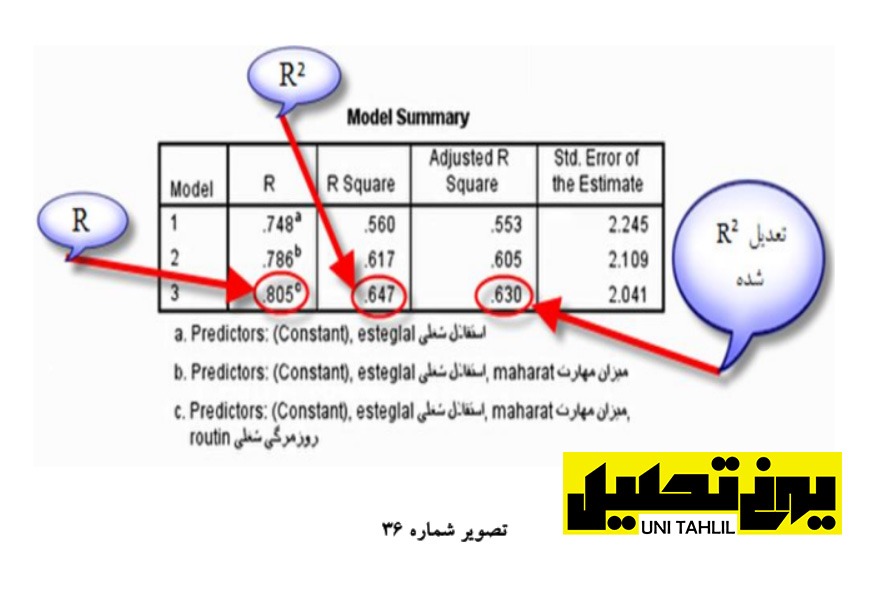
چهارمین جدول از این پنجره جدول ضرایب Coefficients است این جدول گویای ضرایب متغیرها است در این جدول ما یک B داریم یک نشانگر Beta است Beta ازاین جهت برای کاربر دارای اهمیت است که میزان استانداردشده است به عبارتی بر طبق این جدول اگر متغیرها را در مسیری مشخص در یک مدل قرار دهیم میزان فلش استقلال شغلی 57/0 است میزان فلش مهارت196/0 است که میتوان آن را به 2/0 گرد نمود و فلش روزمرگی شغلی 21/0 -است (تصویر شماره 38 ).
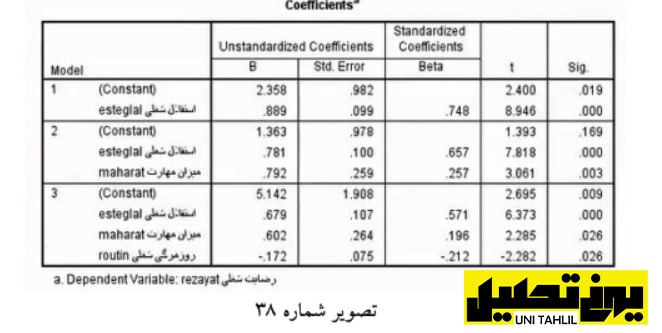
بر طبق داده های جدول Coefficients و ستون Beta آن میتوانیم بخشی از مدل خود را بسازیم همچنین مطابق ستون Sig تمام متغیرهای میانی و مستقل که وارد شدند دارای اهمیت هستند و معنی دار میباشند لذا بر اساس میزان Beta ما میتوانیم مدل خود را بسازیم که چیزی شبیه تصویر 39 است.
بین ضرایب واردشده متغیرها بیشترین ضریب متعلق به استقلال است با 57/0 لذا استقلال شغلی را میتوان برای رگرسیون دوم انتخاب نمود به عبارتی استقلال شغلی را به عنوان متغیر وابسته و روزمرگی و میزان مهارت را به عنوان متغیر مستقل انتخاب مینماییم و درواقع از استقلال به سمت چپ مدل را ادامه میدهیم و کامل میکنیم لذا برای این کار مجدداً به رگرسیون بازمیگردیم بدین ترتیب که با بازگشت به رفحه اصلی مجدداً به قسمت Analyze میرویم و با انتخاب گزینه Regression بار دیگر بر روی گزینه Linear رگرسیون وطی کلیک میکنیم تا پنجره Regression Linea نمودار گردد اما این بار با برگرداندن رضایت شغلی )rezayat )از کادر Dependent به مخزن )رضایت از دفعه قبل در کادر متغیر وابسته مانده از سه متغیر موجود در کادر :(s Independent استقلال شغلی (esteglal را ابتدا به مخزن منتقل نموده سپس به عنوان متغیر وابسته به کادر Dependent منتقل میکنیم با رعایت سایر دستورات دیگر دکمه OK را میزنیم (تصویر شماره 40 )
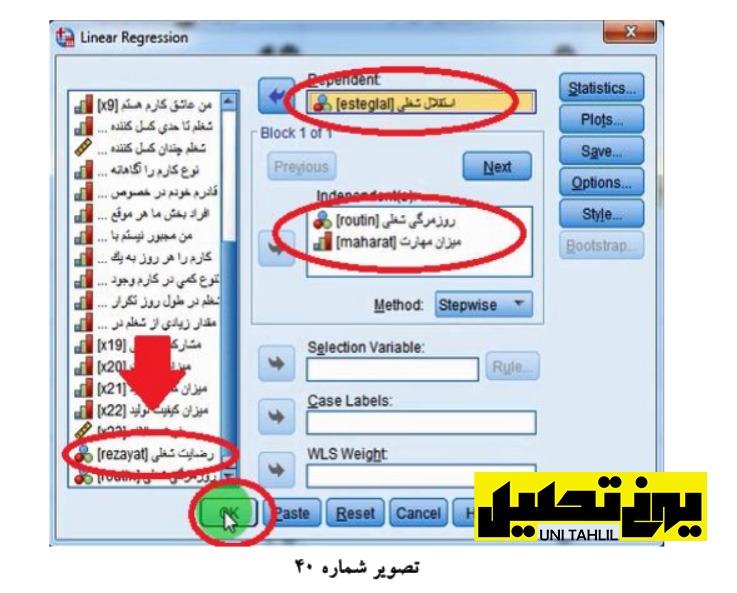
در این مرحله با زدن دکمه OK پنجره خروجی آماره ها Viewer Statistics SPSS IBM نمودار میگردد بر طبق اولین جدول متغیرهای وارد شد/ خارج شده یا Removed/Entered Variables استقلال شغلی درصورتیکه به عنوان متغیر وابسته مدل در نظر گرفته شود فقط روزمرگی شغلی میتواند وارد معادله شود )درحالی که مهارت وارد نمیشود در جدول والرت مدل Summary Model مقدار 2 ضریب همبستگی بندگانه یا R ما 497/0 است R ما 247/0 است و 2 R تعدیل شده 236/0 است میتوان هر سه ضریب را گرد نمود .
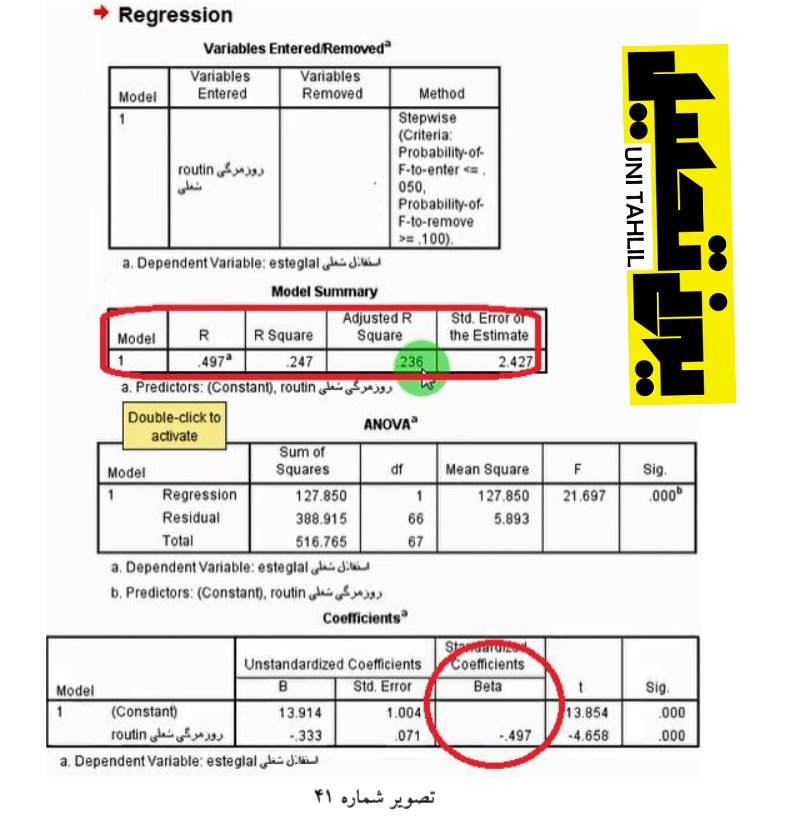
در جدول تحلیل واریانس« ANOVA یک متغیر بیشتر وارد نشده لذا یک ردیف بیشتر نداریم در این جدول F ما 21 و Sig سه نفر است به عبارتی داده های این جدول گویای معادله رگرسیونی ما با یک متغیر مستقل روزمرگی شغلی و یک متغیر وابسته استقلال شغلی معنی دار است در جدول ضرایب Coefficients در ردیف روزمرگی شغلی Beta منهای 49 صدم است که میتوان آن را گرد نمود تصویر شماره 41.
در معادله سوم رگرسیونی »روزمرگی شغلی« متغیر وابسته و تنها متغیر باقیمانده که »میزان مهارت« است مستقل میشود برای این منظور با بازگشت به صفحه اصلی داده ها مجدداً از طریق دستور Analyze و انتخاب گزینه Regression بار دیگر بر روی گزینه Linear( رگرسیون خطی( کلیک میکنیم تا پنجره Regression Linear نمودار گردد اما این بار با برگرداندن استقلال شغلی )esteglal )از کادر Dependent به مخزن )باقیمانده از دفعه قبل( از دو متغیر موجود در کادر :(s(Independent« روزمرگی شغلی« )routin )را ابتدا به مخزن منتقل نموده سپس به عنوان متغیر وابسته به کادر Dependent منتقل میکنیم و با رعایت سایر دستورات دیگر دکمه OK را میزنیم (تصویر شماره 42.) انجام مدل تحلیل مسیر به روش سنتی در spss
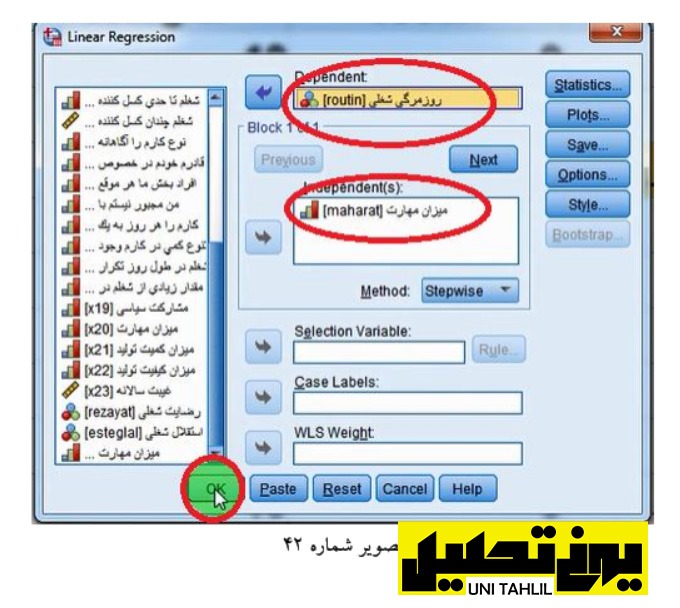
با زدن دکمه OK پنجره آماره ها )Viewe Statistics SPSS IBM )نمودار میگردد بر طبق اولین جدول متغیرهای وارد شد/ خارج شده« یا »«Removed/Entered Variables« میزان مهارت « در معادله ای که وابسته اش روزمرگی شغلی است وارد شده است در جدول خلاصه مدل« )Summary Model )R ما 7 2 R ما نیز 200/0 است و 2 R تعدیل شده برابر با 188/0 است )میتوان هر یک از ضرایب را گرد نمود( جدول »تحلیل واریانس« )ANOVA )نشان میدهد که رگرسیون سوم نیز معنی دار و قابل استفاده است در جدول ضرایب )Coefficients )در ردیف »روزمرگی شغلی« Beta ما 447/0 – است که میتوان آن را به 45/0 گرد نمود (تصویر شماره 43).

همانطور که مقادیر جداول بالا نیز نشان میدهد بر طبق مقدار سطح معنی داری )Sig )حضور متغیر »میزان مهارت« نیز در معادله قابل قبول است لذا میتوان این مورد را به مدل اضافه کرد و بدینوسیله مدل را به پایان برد (تصویر شماره 43).
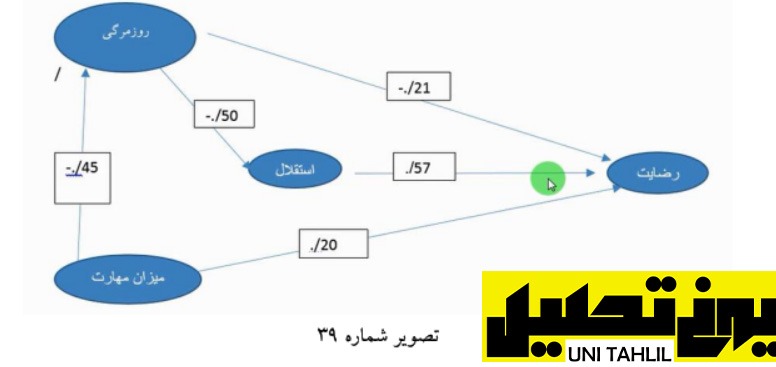
مجموعه دادهها و ضرایب حاصله از رگرسیون اول دوم و سوم را میتوان به شکل مدل زیر خلاصه نمود همانطور که میبینید روزمرگی استقلال و میزان مهارت به عنوان متغیرهای مستقل بر روی رضایت به عنوان متغیر وابسته تأثیر دارند میزان این همبستگی را نیز به شکل ضرایب مثبت و منفی مشاهده میکنید (شکل شماره 44). انجام مدل تحلیل مسیر به روش سنتی در spss
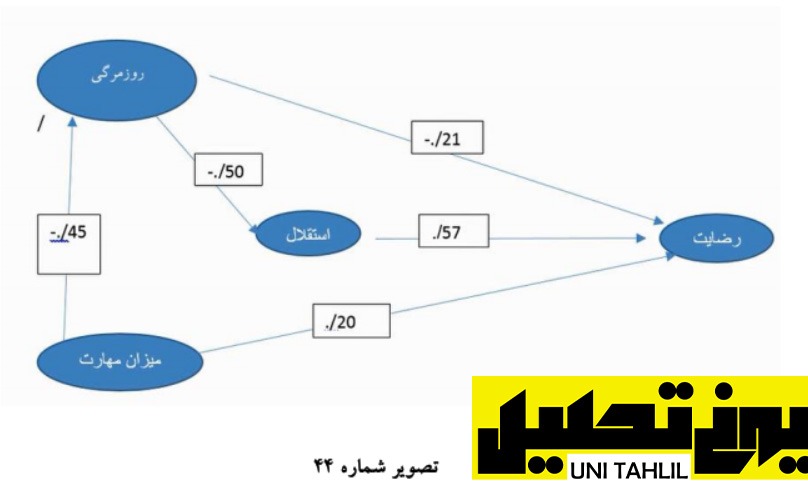
درواقع در استفاده از روش سنتی سه قدم باید برداشت 1 قابلیت اعتماد 2 تحلیل عامل و 3 رگرسیون وطی با پیمودن این مسیر میتوان مدل خود را با استفاده از نرم افزار SPSS ترسیم کرد در این فصل آمووتیم که بگونه میتوان مدل وود را به روش سنتی ترسیم نماییم و درنهایت خروجی خود را در word ترسیم نماییم در نگاه به مدل بالا مشاهده میشود که مهمترین شاخص »استقلال شغلی« با ضریب مستقیم 57/0 است و بعدازآن »روزمرگی شغلی« با ضریب مستقیم 21/0 و درنهایت »میزان مهارت« با ضریب مستقیم 20/0 است البته نباید فراموش کرد که در اندازه گیری تأثیر کامل سازه های مستقل بر سازه »رضایت شغلی« باید اثر یرمستقیم هر یک از سه سازه اثرگذار را هم به دست بیاوریم و در پایان اثر مستقیم و غیرمستقیم هر یک از سازه ها را باهم جمع زده و سپس بر اساس اثرات کل هر یک از سازه ها آنها را با هم مقایسه نماییم اثر غیرمستقیم از حاصل ضرب ضرایب میان مسیر به دست می آید جدول زیر نحوه محاسبه اثر کل را نشان می دهد . انجام مدل تحلیل مسیر به روش سنتی در spss
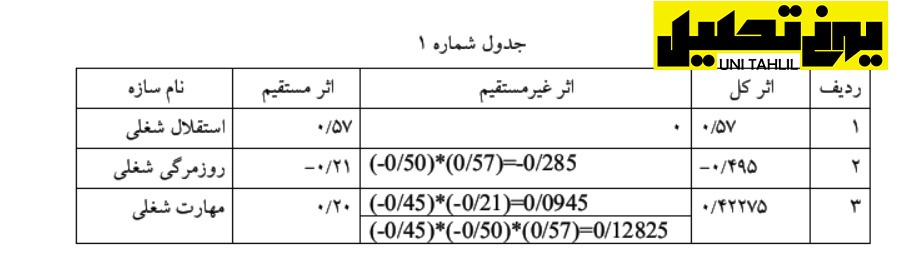
همانطور که جدول بالا میبینید بر اساس ستون اثر کل« نیز سازه »استقلال شغلی« با ضریب 57/0 همچنان مؤثرترین سازه است بعدازآن مهمترین سازه »روزمرگی شغلی« با ضریب کل 495/0 است و در پایان سازه »مهاره شغلی« با ضریب کل 42/0 قرار دارد *آماره های بالا توجه به نکته را به همراه می آورد که اگر بخواهیم برای تغییر »میزان رضایت شغلی« افراد یک مجموعه اقدام نماییم موتور حرکت در افزایش »میزان مهارت شغلی« افراد خواهد بود با افزایش »مهارت شغلی« »رضایت شغلی« نیز بالا میرود )چون اثر مستقیم دارد( با بالا رفتن میزان رضایت شغلی نیز میزان »تنوع شغلی« و در پی آن میزان »استقلال شغلی« آنان و درنهایت میزان رضایت شغلی افزایش خواهد یافت *از علامت مثبت و منفی در تفسیر مدل نهایی استفاده میشود به طور مثال هرچه »روزمرگی شغلی« کمتر شود )به دلیل علامت منفی( )تنوع شغلی بیشتر شود( »رضایت شغلی« افزایش خواهد یافت یا »استقلال شغلی« هرچه بیشتر شود )به دلیل علامت مثبت( میزان »رضایت شغلی« افراد افزایش خواهد یافت (تصویر شماره 44)
…………………………………………………………………………………………………………………….
در ادامه در قسمت های بعدی می توانید مطالب کامل آموزشی نرم افزار AMOS را مشاهده فرمایید:
فصل اول با عنوان انجام مدل تحلیل مسیر به روش سنتی با استفاده از روش های 1 :قابلیت اعتماد .2: تحلیل عامل . 3 .رگرسیونخطی در نرم افزار SPSS
فصل دوم با عنوان «تحلیل عامل مرتبهاول»
فصل سوم با عنوان «تحلیل عامل مرتبهدوم»
فصل بهارم با عنوان «تحلیل مسیر به همراه تحلیل عاملی »
فصل پنجم با عنوان «انجاممدلمعادالتساختاری (باکنترلجنسیت افراد با روشسنتی یا
تفکیکی)»
فصل ششم با عنوان «انجاممدلمعادلات ساختاری(با کنترل جنسیت افراد در شکل ترکیبی)»
فصل هفتم با عنوان « تبدیل داده های خام به داده های کوواریانسی درنرم افزار SPSS »
فصل هشتم با عنوان «معادله ساختاری با سازه وابسته دارای یک متغیر مشاهده شده»
منبع: کتاب پردازش و تحلیل داده با نرم افزار اموس دکتر یحیی علی بابایی
…………………………………………………………………………………………………………………………….


{kind=link}