

سبد خرید من (0 )
واریانس و انحراف معیار
- 5 دی, 1400
- روش تحقیق علوم رفتاری
واریانس و انحراف معیار
موضوع نوشته : واریانس و انحراف معیار
انحراف معیار به چه دردی میخورد؟
انحراف معیار مفهومی است که میزان پراکندگی دادههای یک مجموعه را مشخص میکند و بدین جهت یکی از مهمترین مقیاسهای آماری در زمینه آمار توصیفی به حساب میآید. اگر میانگین برآوردی از نقطه ثقل توزیع دادههای یک مجموعه به دست میدهد، و از این رو مقیاسی تکبعدی برای برآورد یک مجموعه دادهها فراهم میسازد، میتوان گفت که انحراف معیار نیز میزان پراکندگی دادهها از نقطه میانگین را نشان میدهد و از این رو مقیاسی دوبعدی برای برآورد توزیع دادهها در اختیار ما قرار میدهد.
واریانس و انحراف استاندارد هر دو معیارهای پراکندگی یا پراکندگی مجموعه ای از نقاط داده هستند. آنها اطلاعاتی در مورد میزان انحراف مقادیر در یک مجموعه داده از مقدار میانگین (متوسط) ارائه می دهند. این مفاهیم معمولاً در آمار برای تعیین کمیت تنوع در یک مجموعه داده استفاده می شود.
واریانس:
واریانس یک اندازه گیری آماری است که میانگین مجذور اختلاف بین هر نقطه داده و میانگین مجموعه داده را محاسبه می کند. این به شما ایده می دهد که چه مقدار نقاط داده از میانگین پخش شده اند. واریانس بالاتر نشان دهنده تنوع بیشتر در بین نقاط داده است.
انحراف معیار:
انحراف معیار جذر واریانس است. این معیار قابل تفسیرتر برای پراکندگی داده ها است زیرا در همان واحد داده های اصلی است. به عبارت دیگر، اندازه گیری میانگین فاصله بین هر نقطه داده و میانگین را ارائه می دهد. انحراف استاندارد بزرگتر نشان دهنده نقاط داده پراکنده بیشتر است.
انحراف استاندارد اغلب بر واریانس در کاربردهای عملی ترجیح داده می شود زیرا مستقیماً با داده های اصلی قابل مقایسه است و در واحدهای مشابه بیان می شود.
هم واریانس و هم انحراف معیار ابزارهای مهمی برای درک توزیع داده ها، شناسایی نقاط پرت و تصمیم گیری آگاهانه بر اساس تنوع داده ها هستند.
مثال
برای مثال اگر یک معلم هستید، احتمالاً برایتان مهم است که بدانید دانشآموزان شما در امتحانی که اخیراً گرفتهاید چه عملکردی داشتهاند. اگر 20 یا 30 دانشآموز داشته باشید با نگاه کردن به تکتک نمرات شاید نتوانید برآورد صحیحی از عملکرد کل کلاس به دست آورید، ولی مسلماً در صورتی که میانگین نمرههای همه دانشآموزان را محاسبه کنید، میتوانید بدانید که وضعیت کل کلاس چگونه بوده است. برای مثال اگر میانگین نمرههای کلاس برابر با 12.5 باشد و میانگین محاسبه شده برای امتحان قبلی 14 بوده باشد، نشان دهنده افت نمرات است و نیاز به چارهجویی وجود دارد.
شما به عنوان یک معلم باید با کدام دانشآموزان بیشتر کار کنید؟ مسلماً برای دانشآموزانی که عملکرد بهتری دارند نیاز چندانی به تلاش بیشتر وجود ندارد، اما به دانشآموزانی که عملکرد ضعیفتری دارند میبایست توجه ویژهای صورت بگیرد. اما چگونه میتوان فهمید که کدام دانشآموزان عملکرد بالاتر دارند، متوسط هستند یا عملکرد ضعیفتری دارند؟ پاسخ به این سؤال از طریق محاسبه انحراف معیار است. انحراف معیار مقیاسی به دست میدهد که با استفاده از آن میتوانیم بدانیم میانگین اختلاف عملکرد دانشآموزان از نقطه میانگین کلاسی چقدر است.
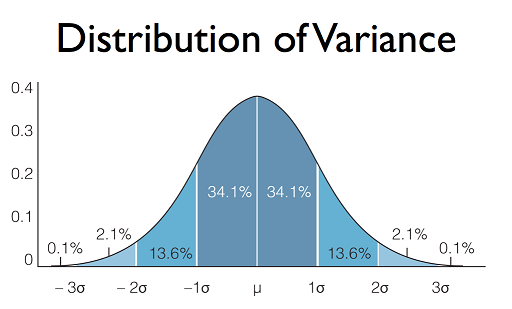
برای مثال فرض کنید در کلاس شما انحراف معیار برابر با 2.5 باشد. اگر توزیع نمرات دانشآموزان به صورت یک توزیع نرمال باشد (که در اغلب موارد در مورد چنین اندازهگیریهایی از توزیع نرمال پیروی میکند)، این عدد نشان میدهد که نمرات بیش از دو سوم یا 68.2% از دانشآموزان شما در محدوده 2.5 + 12.5 قرار دارد. این عدد طبق تعریف انحراف معیار به دست میآید. یک سوم دیگر از دانشآموزان یا نمراتی بالاتر از 15 کسب کردهاند که طبعاً نیاز چندانی به تلاش بیشتر شما ندارند و یا نمراتی زیر 10 کسب کردهاند که مسلماً نیازمند توجه ویژه هستند. بدین ترتیب با محاسبه انحراف معیار نمرههای کلاسی میتوانید دانشآموزان را به سه دسته ضعیف (کمتر از 10)، متوسط (10 تا 15) و قوی (بالاتر از 15) تقسیمبندی کنید.
فرض کنید در مثال فوق تعداد دانشآموزانی که نمرات زیر 10 کسب کرده بودند یعنی مردود بودند برابر با 5 بوده است. همچنین فرض میکنیم معلم با این دسته از دانشآموزان تمرین میکند ولی در امتحان بعدی میانگین نمرات کلاس هنوز همان 12.5 است. شاید در نگاه اول به نظر برسد، تلاشهای وی بینتیجه بوده است؛ اما با محاسبه انحراف معیار میبینیم که این عدد به 1 کاهش یافته است، یعنی نمرات بیش از دوسوم کلاس در محدوده 1 + 12.5 قرار دارد. این به آن معنی است که به احتمال بسیار زیاد تعداد دانشآموزانی که نمره زیر 10 کسب کردهاند، کاهش یافته است.
هر دو مجموعه دادههای آبی و قرمز رنگ میانگینی برابر با 100 دارند ولی انحراف معیار مجموعه دادههای آبی 5 برابر دادههای قرمز است. علامتی که برای نشان دادن انحراف معیار استفاده میشود، حرف یونانی سیگما ” σ ” است. روشی که عموماً برای محاسبه انحراف معیار استفاده میشود از طریق جذر گرفتن از واریانس است. خب اکنون شاید بپرسید واریانس چیست؟
واریانس چیست؟
واریانس به صورت «مقدار متوسط مربع اختلاف مقادیر از میانگین» تعریف شده است. شاید در نگاه نخست تعریف دشواری به نظر برسد! اما هیچ جای نگرانی نیست چون در عمل خواهید دید که مفهوم بسیار سادهای است.
برای محاسبه واریانس، باید گامهای زیر را دنبال کنید:
- ابتدا میانگین را پیدا کنید (میانگین ساده اعداد).
سپس برای هر عدد، مقدار میانگین را از آن تفریق کرده و سپس نتیجه را به توان دو برسانید (مربع اختلاف).
و در نهایت میانگین مربع اختلافات به دست آمده را محاسبه کنید.
واریانس دادهها آماده است. به همین سادگی!
مثال
فرض کنید متصدی یک محل نگهداری از سگها میخواهد قد سگهای موجود را به منظور خاصی اندازهگیری کند. نتایج این اندازهگیری قد (از شانه) به شرح زیر است:
300، 430، 170، 470 و 600 میلیمتر
اینکمیخواهیم میانگین، واریانس و انحراف معیار این دادهها را پیدا کنیم. گام اول یافتن میانگین است:
پس میانگین قد همه سگها برابر با ۳۹۴ میلیمتر است. اکنون خط میانگین را روی شکل رسم میکنیم:
اکنون اختلاف قد هر کدام از سگها را از مقدار میانگین حساب میکنیم:
برای محاسبه واریانس، اختلاف تکتک دادهها را به توان دو رسانده و سپس میانگین میگیریم:
پس، واریانس برابر است با: ۲۱۷۰۴
و انحراف معیار همان جذر واریانس است، پس:
و اما نکته خوب در مورد انحراف معیار، سودمند بودن آن است. اکنون میتوانیم بفهمیم قد کدام سگها در محدوده یک انحراف معیار میانگین (۱۴۷ میلیمتر) قرار دارد.
پس با استفاده از انحراف معیار، ما یک راه “استاندارد” برای یافتن محدوده مقادیر نرمال، مقادیر بیش از نرمال و مقادیر کمتر از نرمال در دست داریم.
اما زمانی که به همه اعضای یک مجموعه دسترسی نداشته باشیم از نمونهگیری استفاده میکنیم. نمونهگیری به معنی انتخاب تصادفی برخی از اعضای یک مجموعه بزرگ (جامعه آماری نامیده میشود) است که در محاسبههای آماری به عنوان مثالی گویا از کل نمونه در نظر گرفته میشود و در این حالت برای محاسبه انحراف معیار و واریانس تفاوتی اندک وجود دارد. برای نمونه در مثال سگها مجموعه دادههای ما مربوط به یک جمعیت بود (۵ سگ تنها سگهای مورد بررسی بودند). اما اگر دادههای ما یک نمونه یعنی یک جمعیت کوچک در نظر گرفته شده از یک جمعیت بزرگتر، برای مثال 5 سگ که از میان 50 سگ به صورت تصادفی انتخاب شدهاند باشد، در این صورت محاسبات تغییر مییابند.
وقتی N داده وجود داشته باشند، هنگام محاسبه واریانس مجموع مربعات اختلاف از میانگینها بر N تقسیم میشوند. اما هنگامی که قرار باشد این محاسبات بر روی نمونهای از یک جامعه آماری انجام یابد مجموع مربعات اختلاف از میانگینها بر N-1 تقسیم میشود. در این حالت باقی محاسبات از جمله روش محاسبه میانگین به همان شکل میماند.
مثال: اگر ۵ سگ موجود فقط نمونهای از جمعیت بزرگتر سگها باشد، مقدار را به جای ۵، باید بر ۴ تقسیم کنیم:
واریانس نمونه: ۱۰۸۵۲۰/۴ = ۲۷۱۳۰
انحراف معیار نمونه = ۲۷۱۳۰√ = ۱۶۴ (نزدیکترین داده)
دلیل این منهای یک کردن، خارج از حوصله این نوشته است و برای اطلاعات بیشتر میتوانید به لینکهای انتهای نوشته مراجعه کنید.
فرمولها:
در ادامه فرمولهای ریاضی حالت کلی محاسبه انحراف معیار برای هر دو حالت جمعیت و نمونه آماری ارائه شده است:
گرچه پیچیده به نظر میآید، اما ما قبلاً آن را به طرز بسیار سادهای محاسبه کردهایم. تنها تفاوت مهم، تقسیمبر N-1 (بجای N) هنگام محاسبه واریانس نمونه است.
چرا اختلاف از میانگینها را به توان دو میرسانیم؟
اگر ما تنها اختلافها را میانگینگیری میکردیم… اعداد منفی، اعداد مثبت را خنثی میکردند:
پس این راهحل درست نیست. اما آیا از قدر مطلق مقادیر میتوانیم استفاده کنیم؟
همانطور که میبینید به نظر میرسد انحراف میانگین به طور صحیحی محاسبه شده است؛ اما در مورد حالت زیر چه میتوان گفت؟
میبینید که مقدار انحراف معیار همچنان ۴ محاسبه شده است، در حالی که اختلاف میانگینها بسیار پراکندهتر است.
در نهایت میبینیم که مربع کردن هر اختلاف و محاسبه جذر در آخر روش بهتری محسوب میشود.
مفهوم هندسی انحراف معیار
انحراف معیار هنگامی که پراکندگی دادهها بیشتر افزایش مییابد و این به واقعیت نزدیکتر است. در واقع این روش یک ایده شبیه «فاصله بین نقاط» است؛ فقط به طریق دیگری اعمال میشود. از طرف دیگر اعمال جبری روی مربعات و جذرها آسانتر از مقادیر قدر مطلق است و بدین ترتیب محاسبه انحراف معیار در بخشهای مختلف محاسبات ریاضی و دیگر علوم آسانتر میشود.
مقالعه ای که در بالا آن را مطالعه فرمودید مربوط به بحث واریانس و انحراف معیار است ،که تیم تحلیلی یونی تحلیل آن را برای شما عزیزان و پژوهشگران گرد آوری کرده است.
روش تحقیق در علوم رفتاری


{kind=link}