

سبد خرید من (0 )
رگرسیون چندگانه در SPSS
- 8 دی, 1400
- SPSS, روش تحقیق علوم رفتاری
رگرسیون چندگانه در SPSS
رگرسیون چندگانه در SPSS
تکنیک یا روش «رگرسیون خطی چندگانه» (Multiple Linear Regression) یکی از موثر و پرکاربردترین روشهای تحلیل چند متغیره محسوب می شود. در روش گرسیون خطی چندگانه، یک رابطه خطی بین «متغیر وابسته» (Dependent Variable) با یک یا چند «متغیر مستقل» (Independent Variable) برقرار میشود. البته گاهی به متغیر وابسته، «متغیر پاسخ» (Respond Variable) و به متغیرهای مستقل، «متغیرهای پیشگو» (Predictor Variables) نیز میگویند. روش رگرسیونی را «چند گانه» (Multiple Linear Regression) میگویند اگر چندین متغیر مستقل قابلیت پیشگویی متغیر وابسته را داشته باشند و بتوان رابطه را به صورت خطی در نظر گرفت. با توجه به کاربرد گسترده این تکنیک، در این نوشتار به بررسی یک مثال و تحلیل رگرسیون چندگانه در SPSS خواهیم پرداخت.
رگرسیون چندگانه در SPSS
همانطور که در دیگر نوشتههای فرادرس خواندهاید، رگرسیون چندگانه، روشی برای توصیف مدل رابطه خطی بین متغیرهای مستقل با یک متغیر وابسته است. در حالت کلی چنین مدلی به همراه خطای تصادفی به صورت زیر نوشته میشود.
y=β0+β1×1+⋯+βpxp+ε
در رابطه بالا، متغیرهای x1
تا xp نقش متغیرهای مستقل را دارند. از طرفی متغیر y نیز متغیر وابسته است. در انتها نیز ε جمله خطای مدل رگرسیونی محسوب میشود. ضرایب β1 تا βp نیز ضرایب مدل رگرسیونی برای متغیرهای متناظر محسوب میشوند. البته توجه داشته باشید که منظور از β0 ، مقدار ثابت یا متوسط کارایی فرد بدون در نظر گرفتن هر یک از متغیرهای مستقل است.
جهت دانلود پکیج آموزشی تحلیل رگرسیون خطی و رگرسیون خطی چندگانه کلیک کنید .
در ادامه به بررسی مثالی خواهیم پرداخت که مربوط به ایجاد یک رابطه خطی از متغیرهای مستقل «هوش» (Intelligence) با نام iq و برچسب Outcome of IQ test، «فعالیت گروهی» (Social Support) با نام soc و برچسب Outcome of social support test و «ابتکار» (Motivation) با نام mot و برچسب Outcome of job motivation test با متغیر وابسته «کارایی شغلی» (Job Performance) با نام perf با برچسب Outcome of Job performance test است.
نکته: از آنجایی که در نرمافزار SPSS نتایح ظاهر شده در خروجی را براساس برچسب هر یک از متغیرها نشان میدهد، اسامی برچسبهای هر یک از متغیرها را ذکر کردهایم.
ایجاد و برآورد ضرایب رگرسیون در چنین مدلی، رابطه خطی بین متغیرهای مستقل و وابسته را آشکار کرده و امکان پیشگویی کارایی شغلی را برای افرادی که قرار است به تازگی استخدام شوند، فراهم میآورد. برای شروع کار ابتدا باید فایل نمونه را از اینجا دریافت کنید. این فایل با فرمت فشرده و از نوع فایلهای اطلاعاتی SPSS است. در تصویر زیر چند سطری از این «مجموعه داده» (Data set) دیده میشود.
البته مشخص است که منظور از متغیر شماره ۱ در اینجا همان کارایی شغلی است که در مدل به عنوان متغیر وابسته در نظر گرفته خواهد شد. همچنین متغیرهای ۲ و ۳ و ۴ به ترتیب مقدار هوش، ابتکار و فعالیت گروهی را برای هر کارمند مشخص میکنند. برای مشخص شدن خصوصیات هر یک از این متغیرها از دستور Descriptive از فهرست Analysis و گزینه Descriptive Statistics استفاده میکنیم. کافی است همه متغیرها را در کادر (variable(s قرار داده و دکمه Ok را بزنید.
نکته: اجرای دستورات SPSS به کمک پنجره دستورات یا Syntax نیز میسر است. به منظور دریافت آمارههای توصیفی با استفاده از خط فرمان، مشابه پنجره Descriptive، کافی است کد زیر را در پنجره Syntax وارد و اجرا کنید.
DESCRIPTIVES VARIABLES=perf iq mot soc /STATISTICS=MEAN STDDEV MIN MAX.
| 1 2 | DESCRIPTIVES VARIABLES=perf iq mot soc /STATISTICS=MEAN STDDEV MIN MAX. |
خروجی به صورت زیر در خواهد آمد. مشخص است که این اطلاعات مربوط به ۶۰ کارمند بوده و «حداقل» (Minimum)، «حداکثر» (Maximum)، «میانگین» (Mean) و «انحراف استاندارد» (Std. Deviation) امتیازات یا مقدارهای مربوط به هر متغیر در جدول قرار گرفته است.
به نظر میرسد که واحدهای اندازهگیری برای هر یک از این امتیازات متفاوت است. بنابراین هنگام اجرای رگرسیون باید اهمیت هر یک از متغیرها را براساس ضریب استاندارد شده آن (که در ادامه مورد بررسی قرار میگیرد) تعیین کرد.
جهت دانلود پکیج آموزشی تحلیل رگرسیون خطی و رگرسیون خطی چندگانه کلیک کنید .
بررسی وجود رابطه خطی بین متغیرهای مستقل و وابسته
قبل از هر تحلیل رگرسیونی، بهتر است با استفاده «نمودار پراکندگی» (Scatter Plot) و همچنین محاسبه ضریب همبستگی، وجود رابطه خطی بین هر یک از متغیرهای مستقل با متغیر وابسته مورد بررسی قرار بگیرد. به این منظور نمودارهای پراکندگی ابزار مناسبی هستند. برای رسم چنین نمواری به طریق زیر عمل میکنیم:
از فهرست Chart گزینه Legacy Dialog را انتخاب کرده و دستور Scatter/Dot را انتخاب میکنیم.
از پنجره ظاهر شده گزینه Matrix Scatter را به منظور ترسیم همزمان نمودار پراکندگی برای متغیرها به صورت ماتریسی انتخاب سپس دکمه Define را کلیک میکنیم.
همه متغیرهای مستقل و وابسته را در کادر Variables قرار دهید. با فشردن دکمه OK، نتیجه در پنجره Output ظاهر خواهد شد.
همانطور که در نمودارها دیده میشود، بین هر یک از متغیرهای مستقل با متغیر وابسته یک رابطه خطی دیده میشود. از طرفی رابطه خطی بین متغیرهای مستقل ضعیف دیده میشود. برای مثال اگر رابطه بین متغیر iq و mot را در نظر بگیریم، به نظر میرسد نمیتوان رابطه خطی بینشان مشاهده کرد. این حالت زمانی که به بررسی همخطی مشغول هستیم مناسب تشخیص داده میشود. اگر لازم است، میتوانید از قالب دستوری برای ترسیم این نمودارها استفاده کنید. کافی است کد زیر را در پنجره Syntax وارد و اجرا کنید.
GRAPH /SCATTERPLOT(MATRIX)=perf iq mot soc /MISSING=LISTWISE.
| 1 2 3 | GRAPH /SCATTERPLOT(MATRIX)=perf iq mot soc /MISSING=LISTWISE. |
حال به بررسی مقدار ضریب همبستگی پیرسون بین متغیرهای مستقل با وابسته میپردازیم. کافی است که از فهرست Analysis گزینه Correlation و سپس دستور Bivariate را انتخاب کنید. در کادر Variables همه متغیرها را قرار داده دکمه OK را کلیک کنید.
همانطور که مشخص است شیوه محاسبه ضریب همبستگی با توجه به فرمول «ضریب همبستگی پیرسون» (Pearson) صورت گرفته و در صورتی مقدار ضریب همبستگی بین هر دو متغیر، در آزمون دو طرفه (Two-tailed) معنیدار باشد، با علامت * مشخص میشوند. خروجی به صورت زیر قابل مشاهده است. در زیرنویس مربوط به این جدول علامت *** نشانگر معنیدار بودن آزمون آماری (رد فرض صفر یا بی معنی بودن ضریب همبستگی) در سطح خطای 0.01 یا سطح آزمون 0.99 است.
همانطور که دیده میشود، رابطه بین متغیرهایی که با رنگ قرمز مشخص شده معنی دار بود ولی بین متغیرهایی که مقادیرشان در کادر آبی قرار دارد، معنی دار نیست. به این ترتیب بین متغیر وابسته (سطر اول) با همه متغیرهای دیگر رابطه خطی به خوبی برقرار است. ولی بین متغیرهای مستقل رابطه همخطی دیده نمیشود. پس مناسب است که به دنبال مدل خطی بین متغیرهای مستقل و وابسته بگردیم تا قادر به پیشگویی مقادیر جدید برای متغیر وابسته باشیم. برای اجرای و نمایش خروجی مربوط به محاسبات ضرایب همبستگی کافی است از کد زیر کمک بگیرید.
CORRELATIONS /VARIABLES=perf iq mot soc /PRINT=TWOTAIL NOSIG /MISSING=PAIRWISE.
| 1 2 3 4 | CORRELATIONS /VARIABLES=perf iq mot soc /PRINT=TWOTAIL NOSIG /MISSING=PAIRWISE. |
اجرای رگرسیون چندگانه
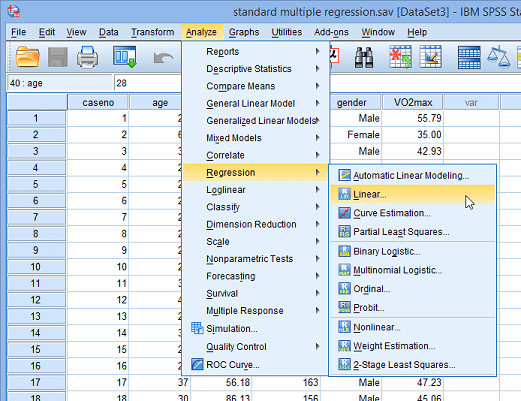
به منظور تحلیل رگرسیون چندگانه در SPSS از فهرست Analysis گزینه Regression و دستور Linear را اجرا میکنیم. متغیر perf را در کادر dependent و بقیه متغیرها را (به جز متغیر name) در کادر (Independent(s وارد میکنیم. برای انجام محاسبات و نمایش نتایج مربوط به «برآورد ضرایب» (Estimates) و «مدل برازش شده» (Model fit) در این مدل با فشردن دکمه statistics گزینهها را مطابق با تصویر زیر انتخاب میکنیم. بررسی مربوط به وجود رابطه خطی بین متغیرهای مستقل که به همخطی معروف است به کمک انتخاب گزینه Colinearity diagnostics میسر میشود. توجه داشته باشید از آنجایی یکی از شرطهای مهم در برآورد پارامترهای رگرسیون خطی به روش OLS یا رگرسیونی کمترین مربعات (Ordinary Least Square) ، نرمال بودن باقیماندهها است. در اینجا برای آزمون تصادفی و استقلال باقیماندهها از آزمون Durbin-Watson استفاده کردهایم.
نکته: نحوه ورود متغیرها در مدل را به صورت Enter انتخاب کردهایم در نتیجه برآورد پارامترهای مدل، برای همه متغیرها صورت خواهد گرفت.
اگر بخواهید این دستورات را به کمک پنجره Syntax را اجرا کنید، باید در پنجره مربوطه کد زیر را وارد و اجرا کنید.
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA COLLIN TOL /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT perf /METHOD=ENTER iq mot soc /RESIDUALS DURBIN.
| 1 2 3 4 5 6 7 8 | REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA COLLIN TOL /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT perf /METHOD=ENTER iq mot soc /RESIDUALS DURBIN. |
در ادامه، خروجیها را به ترتیبی که در پنجره Output ظاهر خواهند شد، توضیح و تفسیر خواهیم کرد. در ابتدا جدول یا گزارشی با نام Variables Entered/Removed ظاهر شده که وظیفه معرفی متغیرهای مستقل و وابسته در مدل را به عهده دارد. از آنجایی که روش ورود متغیرها (Method) در پنجره اصلی از نوع Enter انتخاب شده بود، همه متغیرهای مستقل در مدل به منظور برآورد پارامترها، وارد شدهاند. از آنجایی که این جدول تاثیری در تصمیمات ما نخواهد داشت، از نمایش آن در این نوشتار خودداری کردهایم.
در ادامه، جدول دوم که Model Summary نامگذاری شده است ظاهر میشود. در این جدول ضریب همبستگی (R) و ضریب تعیین (R Square) و … ظاهر میشود.
از آنجایی که ضریب همبستگی (R=0.809) و ضریب تعیین (R Square=0.654) و همچنین «ضریب تعیین اصلاح شده» (0.363=Adjusted R Square) محاسبه شده است، به نظر میرسد که مدل رگرسیونی مناسب است. هر چه این مقدارها به ۱ نزدیکتر باشند، مدل بیانگر رابطه بیشتری بین متغیر وابسته و مستقل است. به بیان دیگر مدل رگرسیونی توانسته درصد بیشتری از تغییرات متغیر وابسته را تحت پوشش قرار داده یا بیان کند. در انتهای جدول نیز ستون Durbin-Watson آماره مربوطه را با مقدار 2.003 نشان میدهد. اگر مقدار این آماره نزدیک به ۲ باشد، نشان از مستقل بودن باقیماندهها خواهد داد. به این ترتیب باز هم شرط دیگری از شروط مربوط به رگرسیون خطی (OLS) برآورده میشود.
در جدول بعدی با نام ANOVA، تحلیل مربوط به واریانس برای مدل رگرسیونی صورت گرفته. با توجه به بزرگ بودن F و مقدار Sig=0.000<0.05 نتیجه میگیریم که مدل رگرسیونی مناسب خواهد بود. زیرا بیشتر تغییرات متغیر وابسته در مدل رگرسیونی دیده شده است. به این معنی که سهم مدل (Regression) در تغییرات کل که در سطر آخر (Total) ستون (Sum of Squares) دیده میشود، به نسبت سهم خطا یا باقیماندهها (Residual) بسیار بیشتر است.
نکته: از آنجایی که مقدار احتمال خطای نوع اول (Error Type I) را 0.05 در نظر گرفتهایم، مقدار Sig را با 0.05 مقایسه کردهایم.
جهت دانلود پکیج آموزشی تحلیل رگرسیون خطی و رگرسیون خطی چندگانه کلیک کنید .
رگرسیون چندگانه در SPSS
در جدول Coefficients، برآورد ضرایب و خصوصیات مربوط به آزمون آنها دیده میشود. همانطور که در جدول زیر مشاهده میکنید، مقدار ثابت Constant در مدل با مقدار 18.131 ظاهر شده است. همچنین مشخص است که ضرایب هر یک از متغیرها مثبت بوده و با توجه به کوچکتر بودن مقدار Sig هر متغیر از مقدار 0.05 فرض صفر بودنشان رد میشود. باز هم این موضوع دلیلی بر مناسب بودن مدل رگرسیونی است. ستون Unstandardize Coefficients که ضرایب واقعی را نشان میدهد با توجه به واحد اندازهگیری هر یک از متغیرها ایجاد شدهاند بنابراین نمیتوان براساس بزرگی هر یک از ضرایب اهمیت متغیر مربوطه در مدل رگرسیونی را تشخیص داد. به این منظور از ستون Standardize Coefficients Beta استفاده میکنیم. هر ضریبی که دارای Beta بزرگتری باشد، در مدل رگرسیونی از اهمیت بیشتری نیز برخوردار است. به این ترتیب مشخص میشود که متغیر mot یا ابتکار (Beta = 0.522) بهترین متغیر برای پیشگویی متغیر وابسته است. به این ترتیب متغیرهای بعدی به ترتیب iq با مقدار (Beta =0.471) و سپس soc نیز با مقدار Beta=0.251 هستند.
با توجه به این ضرایب میتوانیم مدل رگرسیونی را به صورت زیر نمایش دهیم. با استفاده از این رابطه، میتوان برای کارمندان جدید، میزان کارایی را با توجه به ویژگیهای آزمون هوش، ابتکار و فعالیت اجتماعی برآورد کرد.
perf=18.131+0.265iq+0.308mot+0.164soc
نکته: دو ستون آخر این جدول مربوط به بررسی همخطی است. همانطور که میدانید اگر مقدار Tolerance یا میزان تحمل از 0.1 یا VIF بزرگتر از ۱۰ باشد، مدل رگرسیونی از مشکل همخطی رنج میبرد. در حالیکه در جدول خروجی SPSS هر دو این شاخصها گواهی بر عدم وجود همخطی میدهند. بنابراین همانطور که در نمودارهای قبلی وجود همخطی دیده نشد، شاخصهای VIF و Tolerance نیز تایید کننده این موضوع هستند.
در جدول «بررسی همخطی» (Collinearity Diagnostics) سهم هر یک از متغیر در هر بعد برای بیان پراکندگی متغیر پاسخ مشخص شده است. با توجه به این موضع میتوان گفت که iq، اولین متغیر است که بیشترین سهم را در بیان تغییرات متغیر پاسخ دارد، این سهم حدود ۷3 درصد است. دومین متغیر میتواند soc با درصدی حدود 64 در تاثیرگذاری روی متغیرات متغیر وابسته باشد. در مرحله آخر نیز از متغیر mot میتوان به عنوان موثرترین متغیر نام برد. البته در اینجا منظور از سهم هر متغیر در تغییرات متغیر وابسته به صورت مجزا و در هر بُعد در نظر گرفته شده است. مقادیر ویژه ماتریس XTX
نیز در ستون Eigenvalue مشاهده میشود.
نکته: جمع هر ستون (سهم متغیر) در بیان تغییرات کل در همه ابعاد برابر با ۱ است.
در انتهای گزارش نیز جدولی به منظور بررسی توزیع باقیماندهها درج شده. با توجه به شرایط رگرسیونی OLS، باید باقیماندهها دارای توزیع نرمال با میانگین صفر و واریانس ۱ باشند. در جدول زیر وجود چنین شرطی مشاهده میشود.
در سطر دوم و آخر که مربوط به باقیماندهها است، صفر بودن میانگین و برابر با ۱ بودن انحراف استاندارد یا واریانس مشاهده میشود. این مطلب هم دلیلی دیگر بر مناسب بودن مدل ایجاد شده خواهد بود.
نکته: از آنجایی که رابطه رگرسیونی بین ۳ متغیر مستقل با متغیر وابسته برقرار شده است، نمیتوان ترسیمی برای نمایش این رابطه ارائه کرد زیرا احتیاج به فضای چهار بُعدی خواهیم داشت.
که به صورت رایگان در اختیار شما پژوهشگر عزیز قرار میگیرد ابتدا به سبد خرید اضافه کنید و سپس مقاله را دانلود نمایید.
جهت دانلود پکیج آموزشی تحلیل رگرسیون خطی و رگرسیون خطی چندگانه کلیک کنید .
جهت مشاهده جدید ترین آموزش های ویدویی در spss کلیک کنید .
جهت دانلود فصل چهارم پایان نامه همراه با دیتا در چهار نرم افزار Pls , Lisrel , Amos , Spss کلیک کنید .
جهت دانلود پروژه و دیتا همراه با تحلیل در spss کلیک کنید .
جهت دانلود آموزش های رایگان spss کلیلک کنید
روش تحقیق در علوم رفتاری
رگرسیون چندگانه در SPSS


{kind=link}