

سبد خرید من (0 )
رگرسیون لجستیک
- 9 دی, 1400
- SPSS, روش تحقیق علوم رفتاری
رگرسیون لجستیک
موضوع نوشته : رگرسیون لجستیک
رگرسیون لجستیک
همان طور که میدانیم در رگرسیون خطی، متغیر وابسته یک متغیر کمی در سطح فاصلهای یا نسبی است و پیش بینی کننده ها از نوع متغیرهای پیوسته، گسسته یا ترکیبی از این دو هستند. اما هنگامی که متغیر وابسته در کمی نباشد، یعنی به صورت دو یا چندمقولهای باشد، از رگرسیون لجستیک استفاده میکنیم که امکان پیشبینی عضویت گروهی را فراهم میکند. این روش موازی روشهای تحلیل تشخیصی و تحلیل لگاریتمی است. برای مثال، پیش بینی مرگ و میر نوزادان بر اساس جنسیت نوزاد، دوقلو بودن و سن و تحصیلات مادر.
بسیاری از مطالعات پژوهشی در علوم اجتماعی و علوم رفتاری، متغیرهای وابسته از نوع دو مقوله ای را بررسی میکنند. مانند: رأی دادن یا ندادن در انتخابات، مالکیت (مثلاٌ داشتن یا نداشتن کامپیوتر شخصی) و سطح تحصیلات (مانند: داشتن یا نداشتن تحصیلات دانشگاهی) ارزیابی میشود. از جمله حالت های پاسخ دوتایی عبارتند از: موافق- مخالف، موفقیت – شکست، حاضر – غایب و جانبداری – عدم جانبداری.
رگرسیون لجستیک چیست؟
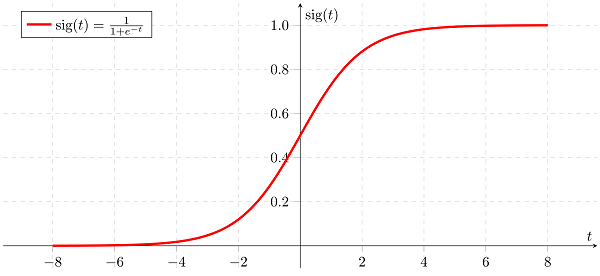
این نوع مدل آماری (همچنین به عنوان مدل لاجیت شناخته می شود) اغلب برای طبقه بندی و تجزیه و تحلیل پیش بینی استفاده می شود. رگرسیون لجستیک احتمال وقوع یک رویداد را بر اساس مجموعه دادهای از متغیرهای مستقل تخمین میزند. از آنجایی که نتیجه یک احتمال است، متغیر وابسته بین 0 و 1 محدود می شود. در رگرسیون لجستیک، یک تبدیل لاجیت بر روی شانس اعمال می شود – یعنی احتمال موفقیت تقسیم بر احتمال شکست. این معمولاً به نام log odds یا لگاریتم طبیعی شانس نیز شناخته می شود و این تابع لجستیک با فرمول های زیر نشان داده می شود:
Logit(pi) = 1/(1+ exp(-pi))
ln(pi/(1-pi)) = Beta_0 + Beta_1*X_1 + … + B_k*K_k
در این معادله رگرسیون لجستیک، logit(pi) متغیر وابسته یا پاسخ و x متغیر مستقل است. پارامتر بتا، یا ضریب، در این مدل معمولاً از طریق تخمین حداکثر درستنمایی (MLE) برآورد میشود. این روش مقادیر مختلف بتا را از طریق تکرارهای متعدد آزمایش می کند تا برای بهترین تناسب شانس ورود به سیستم بهینه شود. همه این تکرارها تابع احتمال ورود به سیستم را تولید می کنند و رگرسیون لجستیک به دنبال به حداکثر رساندن این تابع برای یافتن بهترین تخمین پارامتر است.
هنگامی که ضریب بهینه (یا ضرایب در صورت وجود بیش از یک متغیر مستقل) پیدا شد، احتمالات مشروط برای هر مشاهده را می توان محاسبه، ثبت و با هم جمع کرد تا یک احتمال پیش بینی شده بدست آید. برای طبقهبندی باینری، احتمال کمتر از 0.5 0 را پیشبینی میکند در حالی که احتمال بزرگتر از 0 1 را پیشبینی میکند. پس از محاسبه مدل، بهترین روش ارزیابی میزان خوبی است که مدل متغیر وابسته را پیشبینی میکند، که به آن خوب بودن میگویند. مناسب. آزمون Hosmer-Lemeshow یک روش محبوب برای ارزیابی تناسب مدل است.
تفسیر رگرسیون لجستیک
در تحلیل داده های رگرسیون لجستیک به سختی می توان شانس ورود به سیستم را درک کرد. در نتیجه، افزایش قدرت تخمینهای بتا برای تبدیل نتایج به نسبت شانس (OR)، که تفسیر نتایج را آسانتر میکند، رایج است. OR نشان دهنده شانس وقوع یک نتیجه با توجه به یک رویداد خاص، در مقایسه با احتمال وقوع نتیجه در غیاب آن رویداد است. اگر OR بزرگتر از 1 باشد، این رویداد با شانس بالاتری برای ایجاد یک نتیجه خاص همراه است. برعکس، اگر OR کمتر از 1 باشد، آن رویداد با احتمال کمتری برای وقوع آن نتیجه همراه است.
بر اساس معادله بالا، تفسیر نسبت شانس را می توان به صورت زیر نشان داد: شانس موفقیت با exp(cB_1) برابر برای هر c واحد افزایش در x تغییر می کند. برای استفاده از یک مثال، فرض کنید که ما باید شانس بقا در کشتی تایتانیک را با توجه به اینکه فرد مرد بود، تخمین می زدیم و نسبت شانس برای مردان 0.0810 بود. ما نسبت شانس را اینطور تفسیر می کنیم که شانس بقای مردان در مقایسه با زنان با ضریب 0.0810 کاهش یافته است و همه متغیرهای دیگر را ثابت نگه می داریم.
جهت مشاهده پکیج کامل رگرسیون لجستیک در spss کلیک کنید .
متغیرهای تحلیل رگرسیون لجستیک
در تحلیل رگرسیون لجستیک، همیشه یک متغیر وابسته و معمولا مجموعه ای از متغیرهای مستقل وجود دارند که ممکن است دو مقوله ای، کمی یا ترکیبی از آن ها باشند. به علاوه لازم نیست متغیرهای دو مقوله ای به طور واقعی دوتایی باشند. به عنوان مثال ممکن است پژوهشگران متغیر وابسته کمی دارای کجی شدید را به یک متغیر دومقوله ای که در هر طبقه آن تعداد موردها تقریباً مساوی است تبدیل کنند. مانند آن چه که در مورد رگرسیون چندگانه دیدیم، برخی از متغیرهای مستقل در رگرسیون لجستیک می توانند به عنوان متغیرهای همپراش (covariates) مورد استفاده قرار گیرند تا پژوهشگران بتوانند با ثابت نگه داشتن یا کنترل آماری این متغیرها اثرات دیگر متغیرهای مستقل را بهتر ارزیابی کنند. رگرسیون لجستیک

پیش فرض های رگرسیون لجستیک
با این که رگرسیون لجستیک در مقایسه با رگرسیون خطی پیش فرض های کمتری دارد (به عنوان مثال پیش فرض های همگنی واریانس و نرمال بودن خطاها وجود ندارد)، رگرسیون لجستیک نیازمند موارد زیر است:
هم خطی چندگانه کامل وجود نداشته باشد.
خطاهای خاص نباید وجود داشته باشد (یعنی، همه متغیرهای پیش بین مرتبط وارد شوند و پیش بین های نامربوط کنار گذاشته شوند).
متغیرهای مستقل باید در مقیاس پاسخ تراکمی یا جمع پذیر (cumulative response scale)، فاصله ای یا سطح نسبی اندازه گیری شده باشند (هر چند که متغیرهای دو مقوله ای نیز می توانند مورد استفاده قرار گیرند).
برای تفسیر درست نتایج، رگرسیون لجستیک در مقایسه با رگرسیون خطی نیازمند نمونه های بزرگتری است. با این که آماردان ها در خصوص شرایط دقیق نمونه توافق ندارند. بسیاری پیشنهاد می کنند تعداد افراد نمونه حداقل باید ۳۰ برابر تعداد پارامترهایی باشند که برآورد می شوند. رگرسیون لجستیک
همانطور که همگی ما می دانیم، برای انجام تحلیل رگرسیون خطی، متغیر وابسته باید کمی و سطح سنجش آن فاصله ای/نسبی باشد. اما گاهی اوقات اتفاق می افتد که متغیر وابسته تحقیق در مقیاس فاصله ای نیست و مقیاس آن بصورت اسمی (دو وجهی یا چند وجهی) است. در چنین حالتی برای اینکه بتوانیم عوامل پیش بینی کننده تغییرات یک متغیر اسمی را شناسایی کنیم باید از رگرسیون لجستیک استفاده کنیم. این روش به عنوان روش جایگزین برای روش رگرسیون خطی و همچنین تجزیه تابع تشخیص استفاده می شود.
مفاهیم کاربردی در رگرسیون لجستیک
1- لوجیت (Logit):
مهمترین مفهوم ریاضی در رگرسیون لجستیک، لوجیت است. لوجیت به معنای لگاریتم طبیعی (Ln) بخت های متغیر وابسته (Y) است که مدل آن به مدل لوجیت معروف است. ساده ترین مثال از یک لوجیت را می توان در قالب یک جدول توافقی 2*2 مشاهده کرد. در جدول زیر، توزیع متغیر وابسته شرکت در انتخابات (Y) بر اساس یک متغیر مستقل جنسیت (X) آمده است. در این مثال، لوجیت لگاریتم طبیعی بخت های Y است که مقدار Y را از روی X پیش بینی می کند.
2- آماره والد (Wald):
در رگرسیون لجستیک آماره والد معنی دار بودن حضور هر متغیر مستقل در معادله را نشان می دهد. در نتیجه، آماره والد معادل آماره t در رگرسیون خطی است. آماره والد این فرض صفر را به آزمون می گذارد که مقدار تمامی بتا ها برابر است با صفر. یعنی میزان تأثیر تمامی متغیرهای مستقل بر متغیر وابسته برابر با صفر است. پس اگر قرار است فرض صفر را رد کنیم مقدار حداقل یکی از بتاها نباید صفر باشد.
3- بخت ها (Odds):
بخت ها عبارتند از احتمال رخ دادن یک واقعه بر احتمال رخ ندادن آن واقعه.
برای درک بهتر مفهوم بخت ها، مثال مربوط به مدل لوجیت را تکرار می کنیم. در این مثال بخت شرکت مردان در انتخابات عبارتند از تعداد مردانی که در انتخابات شرکت کرده اند، نسبت به تعداد مردانی که در انتخابات شرکت نکرده اند. در گروه زنان نیز، بخت شرکت زنان در انتخابات برابر است با تعداد زنانی که در انتخابات شرکت کرده اند نسبت به تعداد زنانی که در انتخابات شرکت نکرده اند.
4-نسبت بخت ها (Odds ratio):
در رگرسیون لجستیک برای تعیین میزان تأثیر هر متغیر مستقل بر متغیر وابسته از آماره ای به نام نسبت بخت ها (OR) استفاده می شود. نسبت بخت ها، همانطور که از اسمش مشخص است، نسبت دو بخت نسبت به یکدیگر است و به معنای نسبت احتمال وقوع یک پیامد با فرض عضویت در گروه اول به احتمال وقوع آن پیامد با فرض عضویت در گروه دوم می باشد. به عبارتی، نسبت بخت ها نشان دهنده یک واحد تغییر در بخت های وقوع یک پیامد به ازای یک واحد تغییر در متغیر مستقل است.
در تفسیر نسبت بخت ها در رگرسیون لجستیک باید قواعد زیر را رعایت کنیم:
نکته 1: نسبت بخت ها در خروجی SPSS با نماد Exp(B) نمایش داده می شود.
نکته 2: در تفسیر نتایج نسبت بخت ها باید قواعد زیر را رعایت کنیم.
1- هر گاه نسبت بخت ها بزرگتر از عدد 1 باشد، تغییر متغیرهای مستقل و وابسته مثبت و هم جهت است. یعنی با افزایش مقدار متغیر مستقل، متغیر وابسته نیز افزایش می یابد (در این حالت مقدار B نیز مثبت است).
2- هرگاه نسبت بخت ها کوچکتر از عدد 1 باشد، متغیرهای مستقل و وابسته منفی و در جهت مخالف هم هستند. یعنی با افزایش مقدار متغیر مستقل، مقدار متغیر وابسته کاهش می یابد (در این حالت مقدار B نیز منفی است).
3- هر گاه نسبت بخت ها برابر با عدد 1 باشد، متغیر مستقل تأثیر معنی داری بر متغیر وابسته ندارد و مقدار B یا اثر آن 0 است.
نکته سوم: نسبت بخت ها را می توان به دو صورت زیر تفسیر نمود:
1- در شیوه اول همانگونه که ذکر شد بر اساس نسبت تغییر در متغیر وابسته به ازای یک واحد تغییر در متغیر مستقل تفسیر می کنیم.
2- در شیوه دوم می توان نسبت بخت ها را بصورت درصد تفسیر کرد. برای این کار ابتدا نسبت بخت ها را از عدد 1 کم و سپس در عدد 100 ضرب می کنیم و بصورت درصد تفسیر می کنیم.
جهت مشاهده پکیج کامل رگرسیون لجستیک در spss کلیک کنید .
حجم نمونه در رگرسیون لجستیک
اگرچه در رگرسیون لجستیک قواعد خاصی برای حجم نمونه و نیز حداقل نسبت تعداد نمونه به تعداد متغیر پیش بین پیشنهاد نشده است، اما برخی از متخصصین علم آمار چندمتغیره، حداقل حجم نمونه برای مطلوب رگرسیون لجستیک را 100 نفر و برخی 50 نفر عنوان کرده اند. اما آنچه مسلم است این است که هرچه تعداد متغیرهای مستقل بیشتر باشد حجم نمونه نیز باید بیشتر باشد. همچنین باید در نظر داشت که در رگرسیون لجستیک به حجم نمونه بیشتر از حجم نمونه در رگرسیون خطی نیاز داریم.
نحوه تعریف متغیرهای طبقه بندی شده (اسمی و ترتیبی) در رگرسیون لجستیک رگرسیون لجستیک
یکی از مهمترین مشکلات اجرای تجزیه و تحلیل در رگرسیون لجستیک وجود متغیرهای ترتیبی است. در هنگام اجرای رگرسیون لجستیک فرض بر این است که تمامی متغیرهای مستقل از نوع فاصله ای/نسبی هستند. در حالی که در عمل چنین نیست و برخی از آن ها اسمی و ترتیبی هستند. اما از آنجا که در رگرسیون لجستیک با نسبت احتمال وقوع یک پدیده با احتمال عدم وقوع آن پدیده سرو کار داریم، بنابراین متغیرهای مستقل حتماً باید به متغیرهای شبه فاصله ای (با دو کد 0 و 1) تبدیل شوند تا بتوانیم نسبت طبقات آن در متغیر وابسته را بررسی کنیم. به همین دلیل در نرم افزار SPSS در هنگام اجرای دستور رگرسیون لجستیک از طریق کادر Categorical در کادر اصلی دستور، این امکان وجود دارد که متغیرهای طبقه بندی شده (اسمی و ترتیبی) را بصورت تصنعی به متغیرهای فاصله ای تبدیل کنیم.
برای تصنعی کردن متغیرهای اسمی و ترتیبی، باید هر یک از طبقات یک متغیر به عنوان یک متغیر جداگانه با دو طبقه تعریف شده و به طبقه اول کد 0 و به طبقه دوم کد 1 تعلق می گیرد. به عنوان مثال اگر متغیر مورد نظر ما سطح تحصیلات باشد که بصورت پائین، متوسط و بالا تعریف شود، باید هر گزینه را به عنوان یک متغیر دو وجهی حساب کرده و به کسانی که آن میزان تحصیلات را دارند کد 1 و به کسانی که آن تحصیلات را ندارند کد صفر تعلق می گیرد. یعنی به این صورت
متغیر اول: تحصیلات پائین=1 و تحصیلات غیر پائین=0
متغیر دوم: تحصیلات متوسط=1 و تحصیلات غیر متوسط=0
نکته اول: همانگونه که مشاهده می شود متغیر تحصیلات در هنگام تبدیل به متغیر تصنعی فقط در دو طبقه تعریف شده و طبقه سوم (تحصیلات بالا) حذف شده است. دلیل این امر این است که در رگرسیون لجستیک، همانند رگرسیون خطی، متغیر تصنعی برای طبقه آخر (یعنی بزرگترین کد) تعریف نمی شود و تعداد آن همواره باید یکی کمتر از طبقات متغیر اصلی باشد. طبقه ای که به متغیر تصنعی تبدیل نمی شود طبقه مرجع نام دارد که مبنای مقایسه و تقابل با سایر طبقات قرار می گیرد.
نکته دوم: موقعی که طبقات متغیر مستقل با طبقات مختلف متغیر وابسته به منظور مقایسه در تقابل قرار می گیرند، در هنگام اجرای کادر Categorical در دستور رگرسیون لجستیک امکان انتخاب چندین نوع تقابل وجود دارد:
1- شاخص (Indicator): در این روش، تقابل ها بصورت عضویت یا عدم عضویت در یک طبقه نشان داده می شوند. طبقه مرجع نیز بصورت یک ردیف در ماتریس تقابل با مقادیر 0 نشان داده می شود. این روش رایج ترین روش انتخاب تقابل هاست که اغلب از این روش استفاده می شود.
2- ساده (Simple): در این روش هر طبقه از متغیر پیش بین با طبقه مرجع متغیر وابسته مقایسه می شوند.
3- تفاوت (Difference): هر طبقه از متغیر پیش بین با میانگین اثر طبقات قبلی مقایسه می شود. این روش به معکوس تقابل های هلمرت نیز معروف است.
4- هلمرت (Helmert): هر طبقه از متغیر پیش بین با میانگین اثر طبقات بعدی مقایسه می شود.
5- چندجمله ای (Polynomial): در این روش، که به تقابل های چندجمله ای متعامد نیز معروف است. فرض بر این است که فاصله بین طبقات برابر می باشد. این تقابل ها فقط برای متغیرهای عددی امکان پذیر هستند.
6- انحراف (Deviation): هر طبقه از متغیر پیش بین با اثر کل مقایسه می شود.
انواع رگرسیون لجستیک
در رگرسیون لجستیک، متغیر وابسته می تواند به دو شکل دووجهی و چندوجهی باشد. به همین خاطر در نرم افزار SPSS شاهد وجود دو نوع تجزیه و تحلیل رگرسیون لجستیک می باشیم که بسته به تعداد مقولات و طبقات متغیر وابسته می توانیم از این دو شکل استفاده کنیم:
1- رگرسیون لجستیک اسمی دو وجهی
2- رگرسیون لجستیک اسمی چندوجهی یا چند جمله ای
روش انتخاب متغیرها در رگرسیون لجستیک
در رگرسیون لجستیک، روش های متعددی برای انتخاب و ورود متغیرها به مدل وجود دارند که به ما کمک می کنند تا مشخص کنیم چگونه متغیرهای مستقل وارد تحلیل می شوند و نیز بتوانیم مدل های رگرسیونی مختلفی را روی یک مجموعه متغیر یکسان ایجاد کنیم.
1- روش همزمان (Enter)
2- روش پیش رو مشروط (Forward Conditional)
3- روش پیش رو نسبت درستنمایی (Forward LR)
4- روش پیش رو والد (Forward Wald)
5- روش حذف پسرو مشروط ( Backward Elimination Conditional)
6- روش حذف پسرو نسبت درستنمایی (Backward Elimination Likelihood ratio)
7- روش حذف پسرو والد (Backward Elimination Wald)
جهت مشاهده پکیج کامل رگرسیون لجستیک در spss کلیک کنید .
مقالعه ای که در بالا آن را مطالعه فرمودید مربوط به بحث رگرسیون لجستیک است ،که تیم تحلیلی یونی تحلیل آن را برای شما عزیزان و پژوهشگران گرد آوری کرده است.
جهت مشاهده جدید ترین آموزش های ویدویی در spss کلیک کنید .
جهت دانلود فصل چهارم پایان نامه همراه با دیتا در چهار نرم افزار Pls , Lisrel , Amos , Spss کلیک کنید .
جهت دانلود پروژه و دیتا همراه با تحلیل در spss کلیک کنید .
جهت دانلود آموزش های رایگان spss کلیلک کنید
روش تحقیق در علوم رفتاری


{kind=link}